

在AWS上部署Eclipse Dataspace Components的成本优化策略
AWS Architecture Blog
·

AWS上的Eclipse数据空间组件:数据共享基础知识
AWS Architecture Blog
·

在24小时内,OpenAI、SpaceXAI和Meta将AI变成了价格竞争的赛跑
The New Stack
·
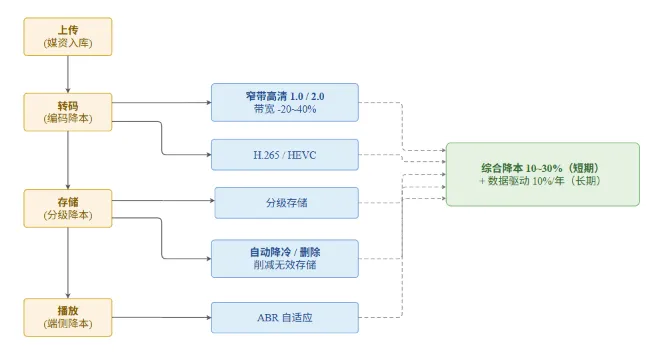
阿里视频云:视频点播成本优化实战
实时互动网
·

如何优化互联网通信云的成本
实时互动网
·
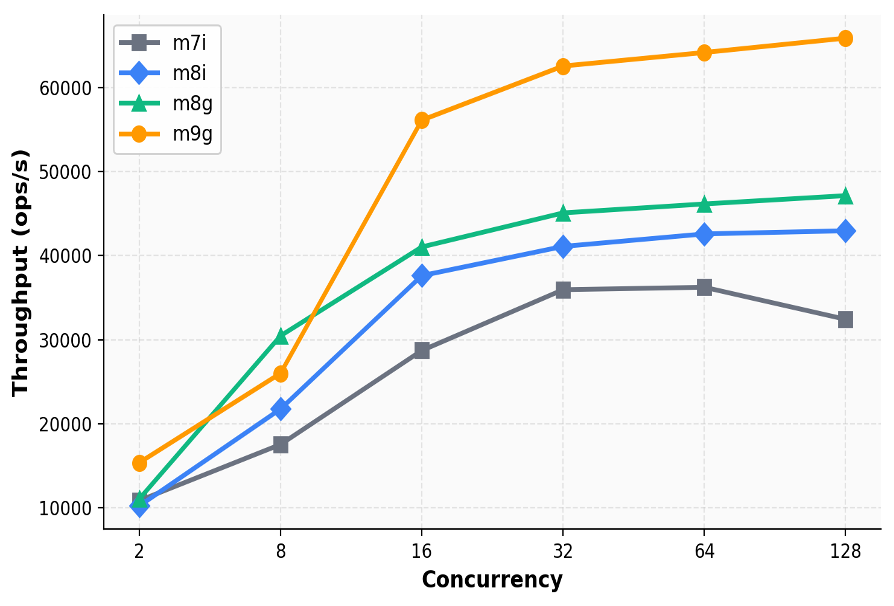
Graviton 优化 Agentic RL 沙箱层:架构与成本优势分析
亚马逊AWS官方博客
·
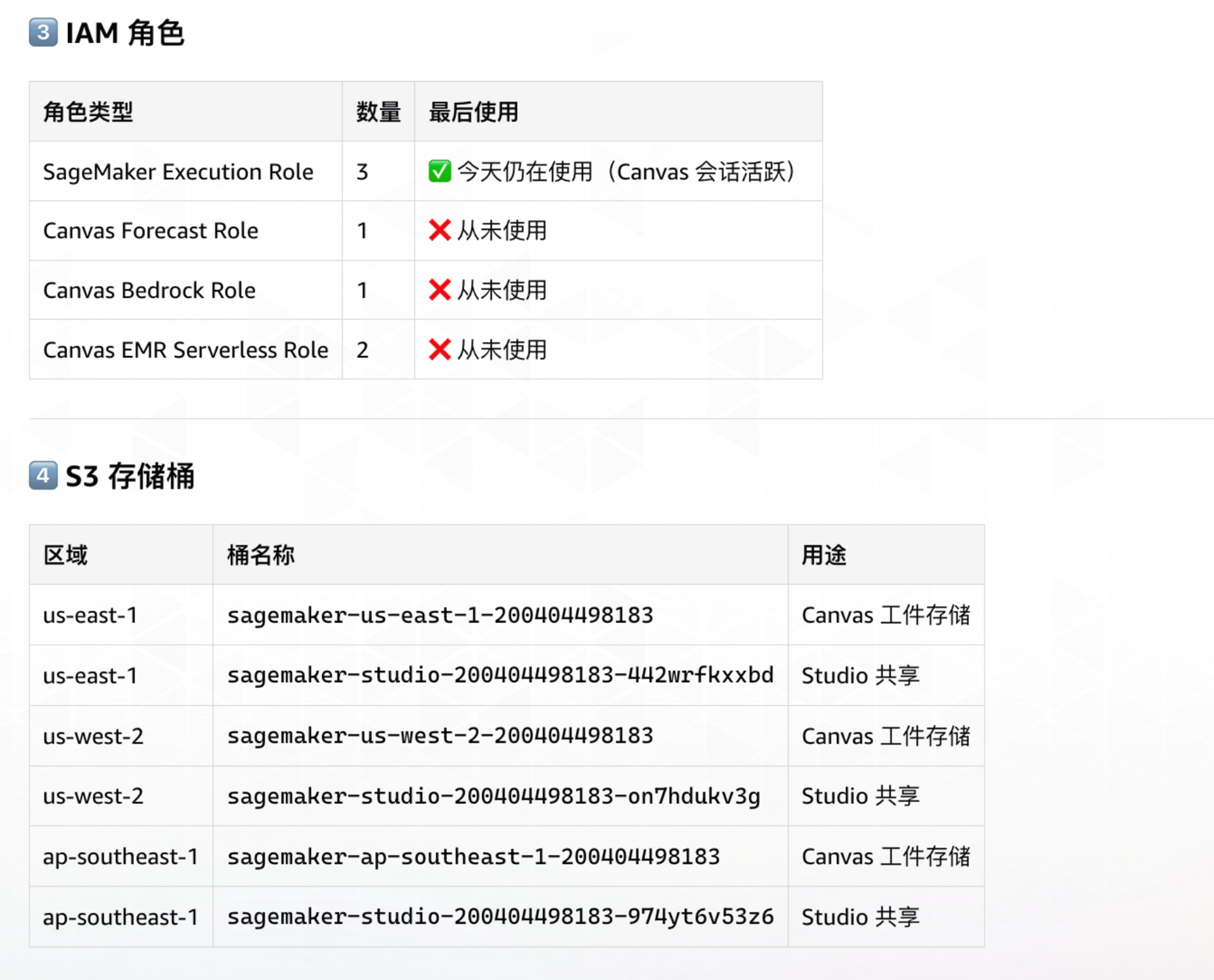
FinOps + DevOps 双Agent — AI驱动的云成本优化实战
亚马逊AWS官方博客
·


哪个CDN直播方案性价比高
实时互动网
·

IBM对企业级AI落地的最新思考与实践
全球TMT-美通国际
·
Tokenmaxxing派对结束,Revenium正在清理残局
The New Stack
·

模型评估:证明您的路由策略确实有效
The DigitalOcean Blog
·

从IDC到云上GPU:基于 Amazon EKS 的大模型推理混合云弹性部署实践
亚马逊AWS官方博客
·

37GAMES 在 Aurora Serverless v2 高可用及成本优化上的实践
亚马逊AWS官方博客
·


SERHANT.的快速AI迭代手册
Vercel News
·

