
评估人工智能在科学研究任务中的能力
内容提要
科学研究的核心在于推理。GPT-5等模型在文献检索和复杂数学证明方面取得了显著进展。新推出的FrontierScience基准旨在评估模型的科学能力,包含高难度问题。初步评估显示,GPT-5.2在Olympiad和Research任务中表现优异,但开放式思维能力仍需改进。未来将继续优化模型,推动科学研究进展。
关键要点
-
推理是科学研究的核心,科学家生成假设并进行测试和改进。
-
GPT-5等模型在文献检索和复杂数学证明方面取得显著进展。
-
FrontierScience基准旨在评估模型的科学能力,包含高难度问题。
-
初步评估显示,GPT-5.2在Olympiad和Research任务中表现优异。
-
当前模型支持结构化推理,但开放式思维能力仍需改进。
-
FrontierScience包含物理、化学和生物学领域的专家验证问题。
-
Olympiad部分评估科学推理能力,Research部分评估实际研究能力。
-
GPT-5.2在FrontierScience-Olympiad和Research中表现最佳。
-
FrontierScience为科学能力提供了标准化的评估框架。
-
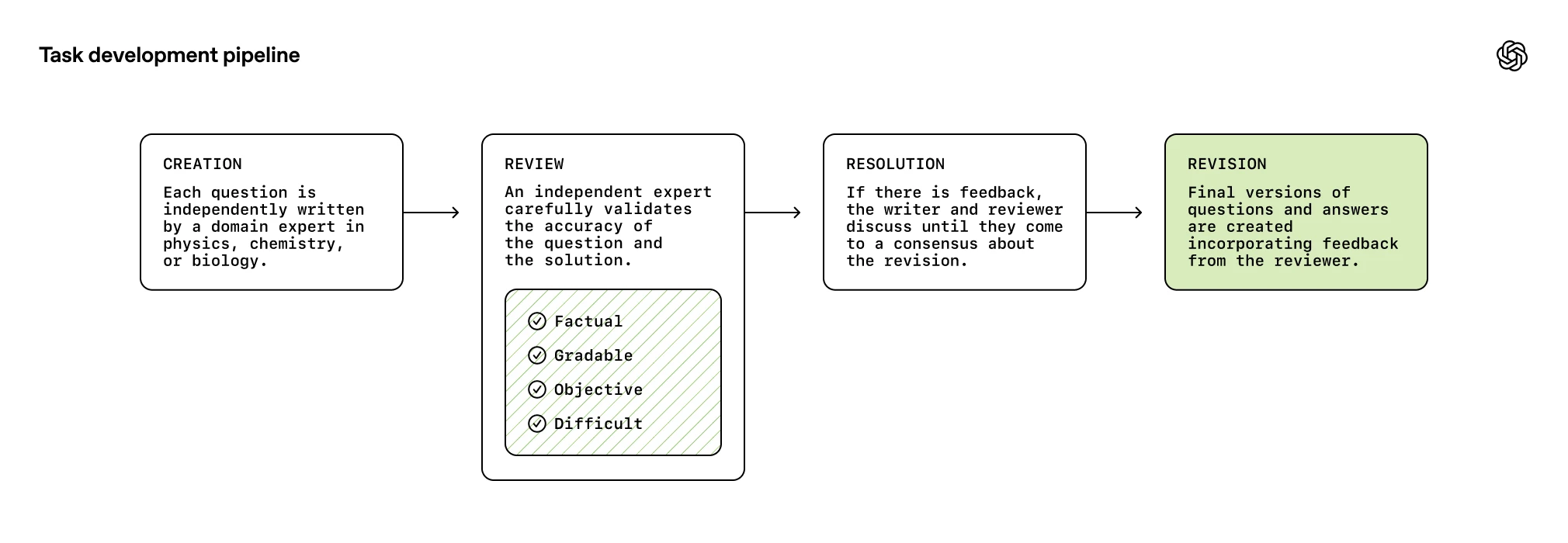
评估过程包括创建、审查、解决和修订四个阶段。
-
使用评分标准评估模型表现,允许对推理步骤进行细致分析。
-
FrontierScience仍有局限性,无法全面反映科学研究的实际过程。
-
未来将继续优化模型,推动科学研究进展。
延伸解读
人工智能在科学研究中的潜力
随着GPT-5等模型在科学推理和文献检索方面的进展,人工智能在科学研究中的应用潜力逐渐显现。这些模型能够加速研究流程,缩短文献检索和复杂数学证明的时间,为科学家提供更高效的工具。然而,当前模型在开放式思维能力上的不足,仍需科学家进行问题框架的设定和验证。
FrontierScience基准的意义
FrontierScience基准的推出为评估人工智能在科学领域的能力提供了标准化框架。通过高难度问题的设置,能够更好地衡量模型的科学推理能力和实际研究能力。这一基准不仅有助于追踪模型的进展,也为未来的优化方向提供了明确的目标。
当前模型的局限性
尽管GPT-5.2在FrontierScience的初步评估中表现优异,但其仍存在局限性。模型主要集中在结构化推理上,缺乏生成新假设的能力。此外,FrontierScience的设计也未能全面反映科学研究的复杂性,未来需要更多的评估工具来补充这一不足。
延伸问答
GPT-5在科学研究中有哪些具体应用?
GPT-5在文献检索和复杂数学证明方面取得了显著进展,能够加速科学工作流程。
FrontierScience基准的主要目的是什么?
FrontierScience基准旨在评估模型的科学能力,特别是通过高难度问题来测量专家级的科学推理能力。
GPT-5.2在FrontierScience基准中的表现如何?
GPT-5.2在FrontierScience-Olympiad中得分77%,在Research部分得分25%,表现优异但仍有改进空间。
FrontierScience基准包含哪些领域的问题?
FrontierScience基准包含物理、化学和生物学领域的专家验证问题。
当前模型在开放式思维能力上存在哪些不足?
当前模型支持结构化推理,但在开放式思维能力方面仍需改进。
未来对模型的优化方向是什么?
未来将继续优化模型,以推动科学研究的进展,特别是在开放式思维和生成新假设方面。
