
数据库迎来了新用户——大型语言模型(LLMs)——他们需要一种不同的数据库
内容提要
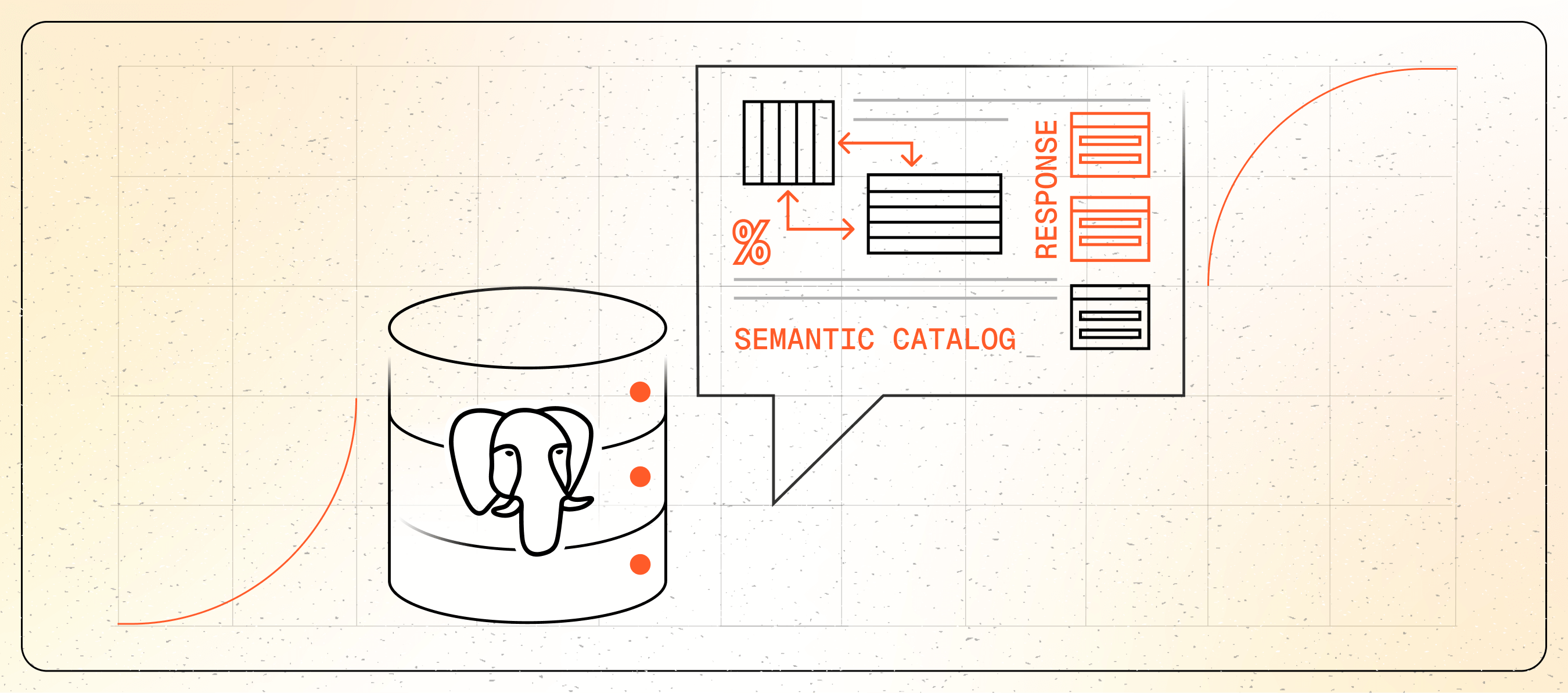
我们正在实验一种基于Postgres的自描述数据库,通过自然语言增强数据库结构的语义。早期测试表明,使用生成的语义目录可提高SQL生成准确性27%。该方法为开发者提供了上下文,改善了LLM对数据的理解,减少了错误。
关键要点
-
正在实验一种基于Postgres的自描述数据库,通过自然语言增强数据库结构的语义。
-
早期测试表明,使用生成的语义目录可提高SQL生成准确性27%。
-
数据库缺乏关于其结构的上下文,导致LLM在生成SQL时容易混淆。
-
解决方案是允许开发者以自然语言描述Postgres中的模式和业务逻辑,提供必要的上下文。
-
自描述数据库的构建围绕四个核心理念:嵌入语义、版本控制描述、自我纠正查询、透明度测量与迭代。
-
实验中使用的语义目录存储自然语言描述,支持动态检索相关上下文。
-
仅依靠模式元素名称进行检索不足以解决问题,因为名称缺乏足够的语义。
-
初步测试显示,使用LLM生成的语义目录显著提高了SQL生成的准确性。
-
每个语义查询遵循四个步骤:描述数据库、人工审核、导入目录、生成SQL。
-
语义上下文对生成正确SQL至关重要,少量上下文信息即可显著提高可靠性。
-
建议从严格控制的函数开始,逐步扩大访问权限以提高准确性。
-
使用Postgres的EXPLAIN命令可以预先捕捉查询错误,提高准确性。
-
未来计划包括自学习目录和动态策略管理,以进一步提升数据库的智能化水平。
延伸解读
语义目录的重要性
在数据库中,语义目录的引入显著提高了SQL生成的准确性。通过自然语言描述数据库结构,开发者能够为大型语言模型(LLM)提供必要的上下文,减少误解和错误。这种方法不仅提升了查询的可靠性,也为开发者提供了更清晰的数据库理解方式。
逐步扩展访问权限的策略
在使用自描述数据库时,建议从严格控制的函数开始,逐步扩大访问权限。这种策略可以有效提高生成SQL的准确性,避免因过多信息导致的混淆。通过逐步验证和扩展,开发者可以在确保系统稳定性的同时,提升数据库的智能化水平。
EXPLAIN命令的自我纠正功能
Postgres的EXPLAIN命令为查询提供了自我纠正的能力,能够在查询执行前捕捉潜在错误。这一功能不仅提高了查询的准确性,还为开发者提供了实时反馈,帮助他们及时调整和优化数据库查询,进一步提升系统的可靠性。
延伸问答
什么是自描述数据库,它的主要特点是什么?
自描述数据库是通过自然语言增强数据库结构的语义,使其能够更好地理解数据。主要特点包括嵌入语义、版本控制描述、自我纠正查询和透明度测量与迭代。
如何提高SQL生成的准确性?
通过使用生成的语义目录,可以提供必要的上下文信息,从而提高SQL生成的准确性,早期测试显示准确性提高了27%。
为什么传统数据库缺乏上下文会导致LLM生成错误的SQL?
传统数据库的结构缺乏足够的上下文信息,导致LLM在生成SQL时容易混淆,无法正确理解表和列之间的关系。
自描述数据库的构建过程包括哪些步骤?
构建自描述数据库的步骤包括:描述数据库、人工审核、导入目录和生成SQL。
使用Postgres的EXPLAIN命令有什么好处?
使用Postgres的EXPLAIN命令可以预先捕捉查询错误,帮助代理自我纠正,从而显著提高查询的准确性。
未来自描述数据库的发展方向是什么?
未来的发展方向包括自学习目录和动态策略管理,以进一步提升数据库的智能化水平。
