
在PostgreSQL中使用pgvector构建向量相似性搜索
内容提要
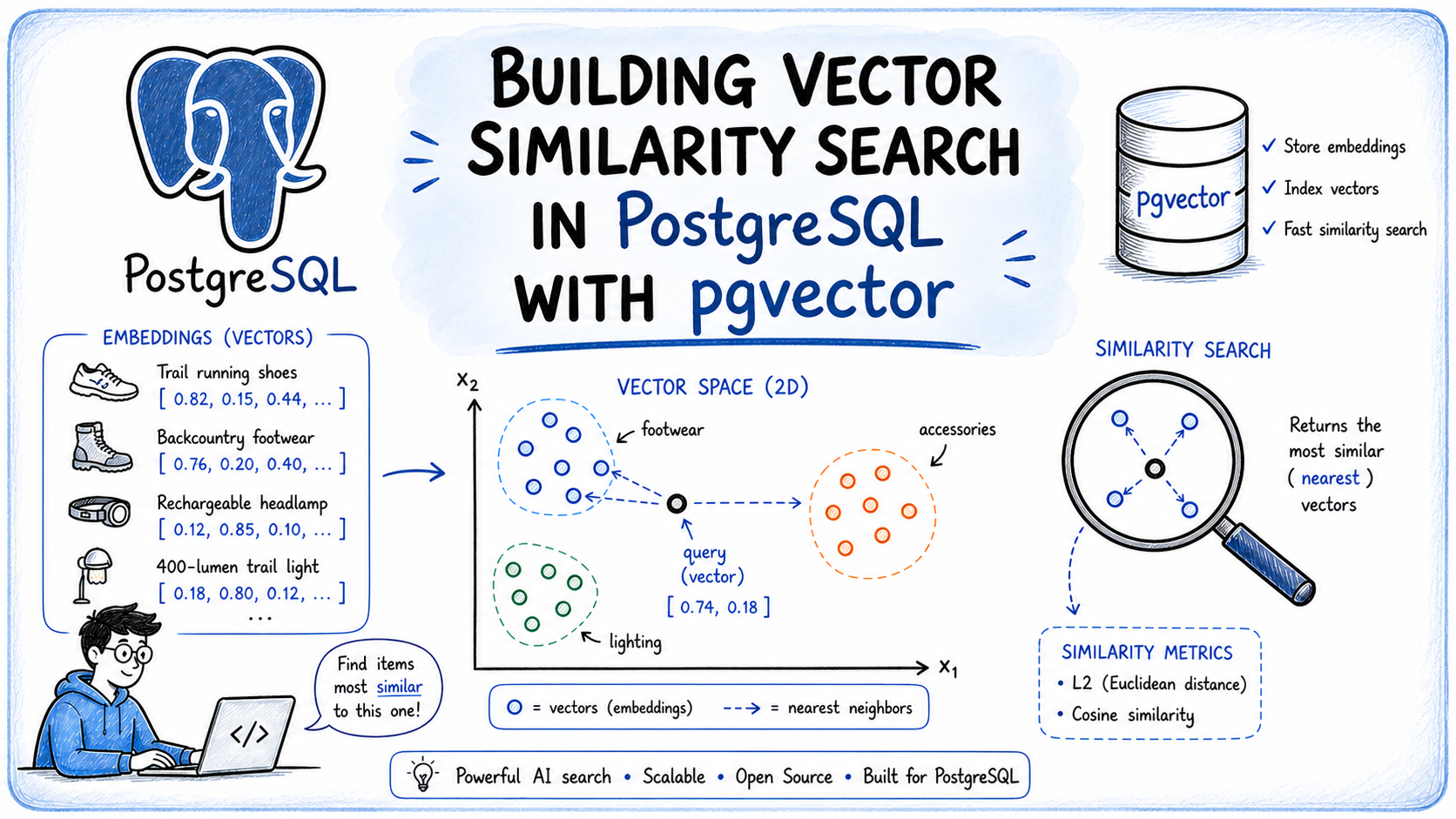
本文介绍了如何在PostgreSQL中使用pgvector扩展进行向量相似性搜索。pgvector支持将向量嵌入与关系数据存储,提供多种距离度量和索引类型。通过示例,展示了创建表、插入数据和执行相似性查询的方法,并结合SQL过滤器提升搜索效果。选择合适的嵌入模型和距离度量至关重要。
关键要点
-
pgvector扩展允许在PostgreSQL中实现向量相似性搜索,基于语义而非关键词匹配。
-
向量嵌入是表示数据含义的浮点数列表,由机器学习模型生成,语义相似的内容在高维空间中靠近。
-
pgvector是一个开源扩展,支持将向量嵌入与关系数据存储,提供多种距离度量和索引类型。
-
安装pgvector后,可以创建包含向量列的表,并插入数据以进行相似性查询。
-
选择合适的距离度量(如L2或余弦距离)对检索质量至关重要。
-
pgvector支持HNSW和IVFFlat两种索引类型,以加速最近邻查找。
-
结合标准SQL过滤器可以提升相似性搜索的效果,允许在查询中使用WHERE子句和JOIN。
延伸解读
向量嵌入的重要性
向量嵌入是实现语义相似性搜索的核心,能够将数据的含义转化为浮点数列表。选择合适的嵌入模型至关重要,因为不同模型生成的向量维度必须与PostgreSQL中的列定义一致。错误的选择可能导致检索效果不佳,影响用户体验。
距离度量的选择
在pgvector中,选择合适的距离度量(如L2或余弦距离)直接影响检索质量。L2距离适合于向量大小有意义的情况,而余弦距离更适合于文本嵌入。理解这些度量的特性可以帮助开发者优化查询结果,提升搜索的准确性。
索引类型的权衡
pgvector提供HNSW和IVFFlat两种索引类型,各有优缺点。HNSW在速度和召回率上表现优异,但内存消耗较大;IVFFlat构建更快且内存占用少,但可能影响召回率。根据数据规模和查询需求选择合适的索引类型,可以显著提升查询性能。
延伸问答
pgvector是什么,它的主要功能是什么?
pgvector是一个开源的PostgreSQL扩展,允许在数据库中实现向量相似性搜索,支持将向量嵌入与关系数据存储。
如何在PostgreSQL中安装pgvector?
可以通过APT包管理器在Debian和Ubuntu上快速安装,或在macOS上使用Homebrew,具体命令为:sudo apt install postgresql-18-pgvector或brew install pgvector。
向量嵌入是什么,它是如何生成的?
向量嵌入是表示数据含义的浮点数列表,由机器学习模型生成,语义相似的内容在高维空间中靠近。
在使用pgvector时,如何选择合适的距离度量?
选择合适的距离度量(如L2或余弦距离)对检索质量至关重要,L2适合有意义的向量大小,而余弦距离更适合文本嵌入。
pgvector支持哪些索引类型以加速查询?
pgvector支持HNSW和IVFFlat两种索引类型,HNSW提供更好的速度与召回率,而IVFFlat构建更快但可能影响召回率。
如何在pgvector中执行相似性查询?
可以使用SQL查询,结合向量距离运算符,例如SELECT name, embedding <-> '[0.80, 0.19, 0.40]' AS distance FROM gear ORDER BY distance LIMIT 3;
