
EvaByte:由 EVA 提供支持的开源 6.5B 先进无标记语言模型
内容提要
EvaByte是一种开源无标记器语言模型,通过字节级处理克服传统标记化的局限,减少数据需求,提高解码速度,支持多种数据格式。在多语言和多模态任务中表现优异,推动了NLP技术的发展。
关键要点
-
标记化是自然语言处理中的基本步骤,但存在处理多语言文本和拼写错误等挑战。
-
EvaByte是一种开源的无标记器语言模型,旨在解决传统标记化的局限性。
-
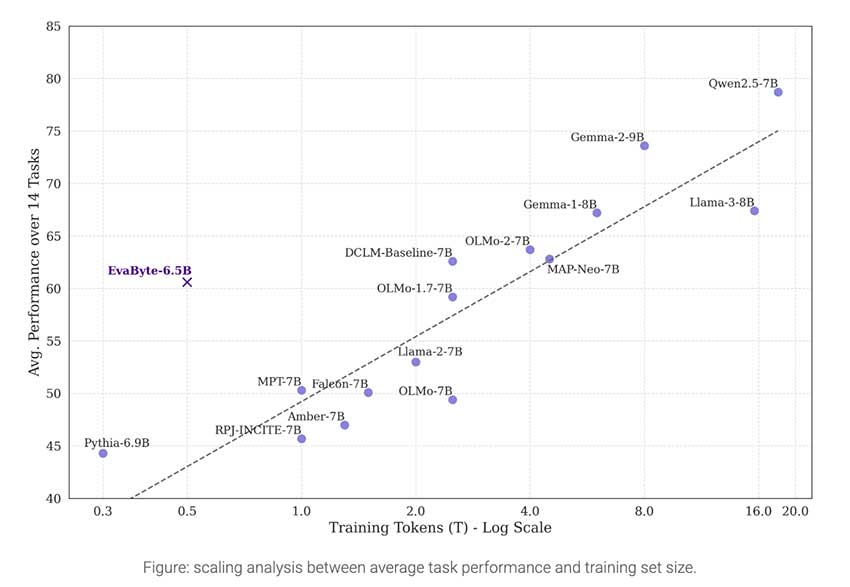
EvaByte采用字节级处理,拥有65亿个参数,数据需求减少5倍,解码速度提高2倍。
-
该模型支持多种数据格式,包括文本、图像和音频,适用于多语言和多模态任务。
-
EvaByte的主要优点包括数据效率、快速解码、多模式功能和稳健性。
-
尽管使用的数据量减少,EvaByte在标准NLP基准测试中表现出色,尤其在多语言场景中。
-
开源版本提供预训练检查点和评估工具,便于研究人员和开发人员使用。
-
EvaByte为传统标记化的局限性提供了解决方案,树立了语言模型的新标准。
延伸解读
无标记化的优势
EvaByte通过字节级处理,克服了传统标记化的局限性,尤其在处理多语言文本和拼写错误时表现出色。这种无标记化的方法不仅提高了模型的稳健性,还简化了数据预处理流程,适合多种数据格式的应用。
开源的影响
EvaByte的开源特性为研究人员和开发者提供了宝贵的资源,允许他们在此基础上进行创新和实验。预训练检查点和评估工具的提供,使得用户能够更容易地集成和应用这一先进的NLP技术,推动了整个领域的发展。
多模态任务的潜力
EvaByte不仅在文本处理上表现优异,还能自然扩展到图像和音频等多模态任务。这种多功能性使其在实际应用中具有更广泛的适用性,尤其是在需要同时处理多种数据类型的场景中,展现出强大的竞争力。
延伸问答
EvaByte是什么类型的语言模型?
EvaByte是一种开源的无标记器语言模型。
EvaByte如何解决传统标记化的局限性?
EvaByte通过字节级处理,消除了标记化带来的不一致性和复杂性。
EvaByte的参数数量是多少?
EvaByte拥有65亿个参数。
EvaByte在多语言任务中的表现如何?
EvaByte在多语言场景中表现优异,尤其在标准NLP基准测试中取得了良好结果。
EvaByte支持哪些数据格式?
EvaByte支持文本、图像和音频等多种数据格式。
EvaByte的开源特性有什么好处?
EvaByte的开源特性促进了协作和创新,使更广泛的社区能够使用先进的NLP功能。
