
LinkedIn如何利用大型语言模型(LLM)为13亿用户提供服务
内容提要
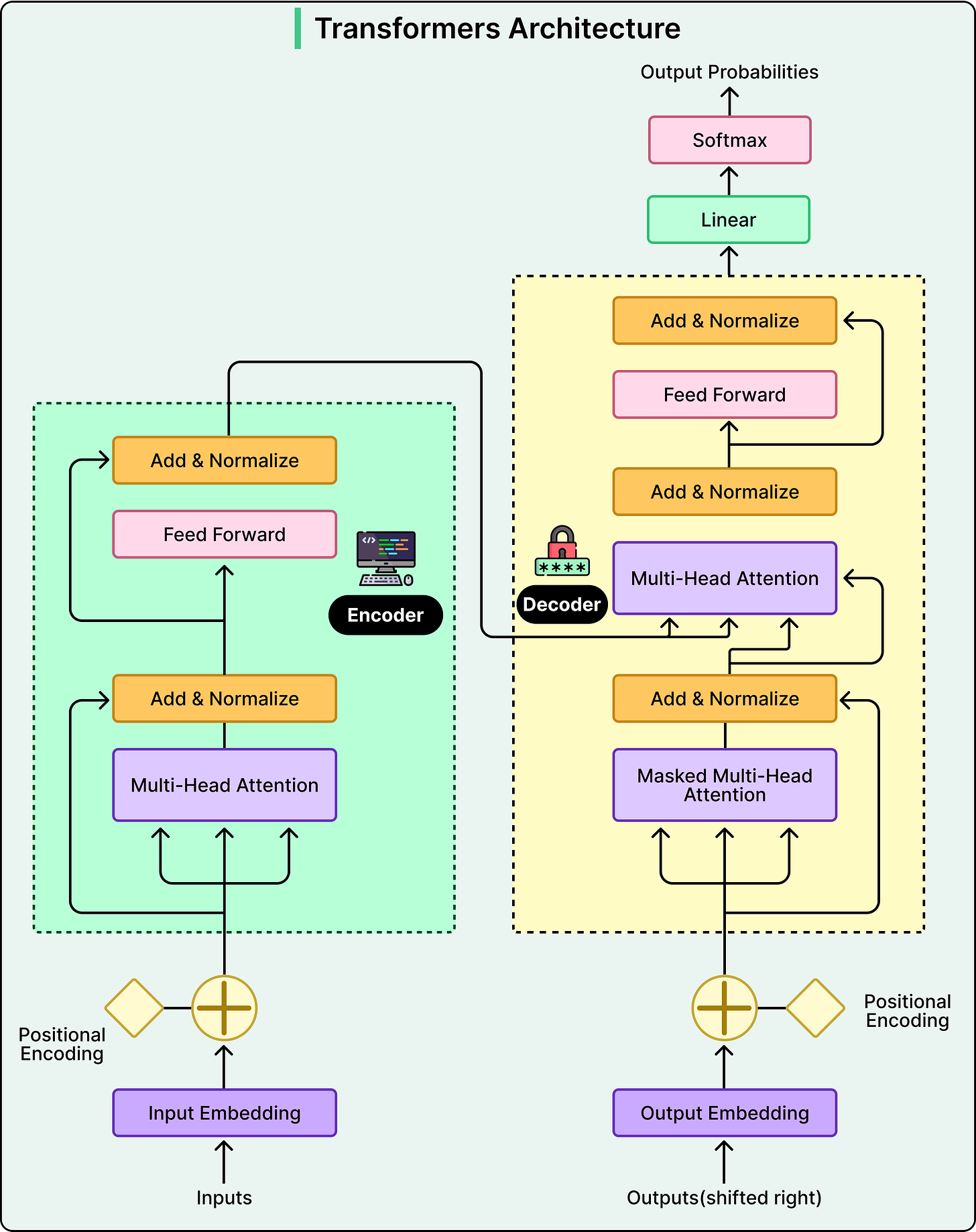
LinkedIn通过将五个独立的内容检索系统整合为一个基于大型语言模型(LLM)的系统,提升了信息推荐的效率和准确性。新系统利用LLM生成的嵌入向量,更好地理解用户兴趣和内容相关性,显著提高了模型的性能和响应速度,使用户能在短时间内获得更相关的内容推荐。
关键要点
-
LinkedIn将五个独立的内容检索系统整合为一个基于大型语言模型(LLM)的系统,以提高信息推荐的效率和准确性。
-
新系统通过LLM生成的嵌入向量,更好地理解用户兴趣和内容相关性,显著提高了模型的性能和响应速度。
-
传统的关键词系统依赖于表面文本重叠,而LLM系统能够理解主题之间的深层关系,尤其在新用户的冷启动场景中表现出色。
-
LinkedIn构建了一个“提示库”,将结构化数据转化为模板化文本序列,以便于LLM处理。
-
通过过滤用户的互动历史,仅保留积极参与的帖子,LinkedIn显著提高了模型的性能和训练效率。
-
LinkedIn的生成推荐模型(GR)将用户的互动历史视为一个序列,理解用户的长期兴趣和时间模式。
-
为了支持大规模的模型,LinkedIn投资了定制基础设施,确保模型在每个用户上都能高效运行。
延伸问答
LinkedIn是如何提升信息推荐的效率和准确性的?
LinkedIn通过将五个独立的内容检索系统整合为一个基于大型语言模型(LLM)的系统,显著提高了信息推荐的效率和准确性。
LLM系统与传统关键词系统有什么区别?
LLM系统能够理解主题之间的深层关系,而传统关键词系统仅依赖于表面文本重叠,无法捕捉到更复杂的内容相关性。
LinkedIn是如何处理用户的互动历史以提高模型性能的?
LinkedIn通过过滤用户的互动历史,仅保留积极参与的帖子,从而显著提高了模型的性能和训练效率。
LinkedIn的生成推荐模型(GR)是如何工作的?
GR模型将用户的互动历史视为一个序列,理解用户的长期兴趣和时间模式,从而提供更相关的内容推荐。
LinkedIn如何确保其推荐系统在大规模用户中高效运行?
LinkedIn投资了定制基础设施,采用共享上下文批处理和多门专家混合模型(MMoE)来高效处理用户历史和候选内容。
LLM在处理结构化数据时遇到了什么挑战?
LLM系统需要将结构化数据转化为文本序列,这一过程涉及到如何有效地将数值特征转化为模型可理解的格式。
