
从”对口型”到”数字人” 音频驱动虚拟人合成技术全景解析
内容提要
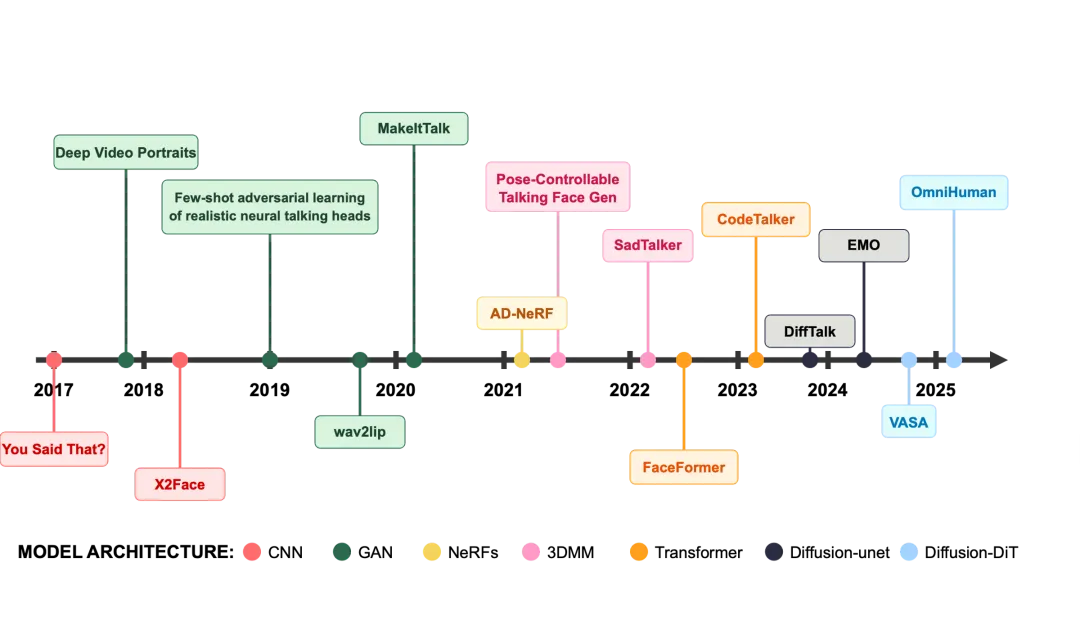
自2021年以来,音频驱动虚拟人合成技术迅速发展,结合静态图像与音频生成同步视频,广泛应用于直播和客服等领域。主要技术挑战包括身份保持与音视频同步。近年来,扩散模型成为主流,推动了该领域的进步。关键研究包括Hallo2、Let Them Talk和OmniHuman-1,分别聚焦于长视频生成、多人人物对话及全身数字人模型,展现出显著的技术突破与商业潜力。
关键要点
-
自2021年以来,音频驱动虚拟人合成技术迅速发展,结合静态图像与音频生成同步视频。
-
主要技术挑战包括身份保持与音视频同步。
-
扩散模型成为主流,推动了该领域的进步。
-
关键研究包括Hallo2、Let Them Talk和OmniHuman-1,分别聚焦于长视频生成、多人人物对话及全身数字人模型。
-
Hallo2在长视频生成中解决了身份漂移问题,显著提高了视觉质量。
-
Let Them Talk首次实现多人对话视频生成,推动了音频驱动虚拟人的应用场景。
-
OmniHuman-1扩展了全身数字人的概念,展示了闭源模型在数据规模上的优势。
延伸解读
技术挑战与解决方案
音频驱动虚拟人合成技术面临的主要挑战包括身份保持和音视频同步。Hallo2通过强化时序注意力机制,有效解决了长视频中的身份漂移问题,确保生成的视频与参考图像高度一致。这一技术突破为长视频生成提供了新的可能性,尤其在直播和影视特效等应用场景中具有重要意义。
数据规模的重要性
在音频驱动虚拟人合成领域,数据规模对模型性能的影响显著。闭源模型如OmniHuman-1的训练数据量达到20,000小时,而开源模型通常仅为1,000小时。这一差距不仅影响生成质量,也反映了当前技术发展的竞争壁垒,强调了数据质量与规模在模型训练中的关键作用。
未来发展方向
音频驱动虚拟人合成技术的未来发展将集中在全身表达力和复杂场景的生成上。研究者们希望实现更细粒度的情绪控制和自然的全身动作生成,同时探索多条件控制的可能性。这些进展将推动数字人技术在实时交互和直播等领域的应用,提升用户体验。
延伸问答
音频驱动虚拟人合成技术的主要应用领域有哪些?
音频驱动虚拟人合成技术广泛应用于直播、客服、影视特效和教育内容制作等领域。
扩散模型在音频驱动虚拟人合成中的作用是什么?
扩散模型成为主流技术,推动了音频驱动虚拟人合成的进步,能够实现高保真和一张图驱动的效果。
Hallo2、Let Them Talk和OmniHuman-1这三项研究的主要贡献是什么?
Hallo2解决了长视频生成中的身份漂移问题,Let Them Talk实现了多人对话视频生成,OmniHuman-1扩展了全身数字人的概念。
音频驱动虚拟人合成技术面临哪些主要技术挑战?
主要技术挑战包括身份保持、音视频同步、时序一致性和自然运动。
如何评测音频驱动虚拟人合成的效果?
评测指标包括视觉质量、音视频同步和动作自然度,常用指标有FVD、FID和CSIM等。
未来音频驱动虚拟人合成技术的发展方向是什么?
未来发展方向包括超越人脸的全身表达力、时间可扩展性、复杂场景的自然生成和强化学习集成。
