
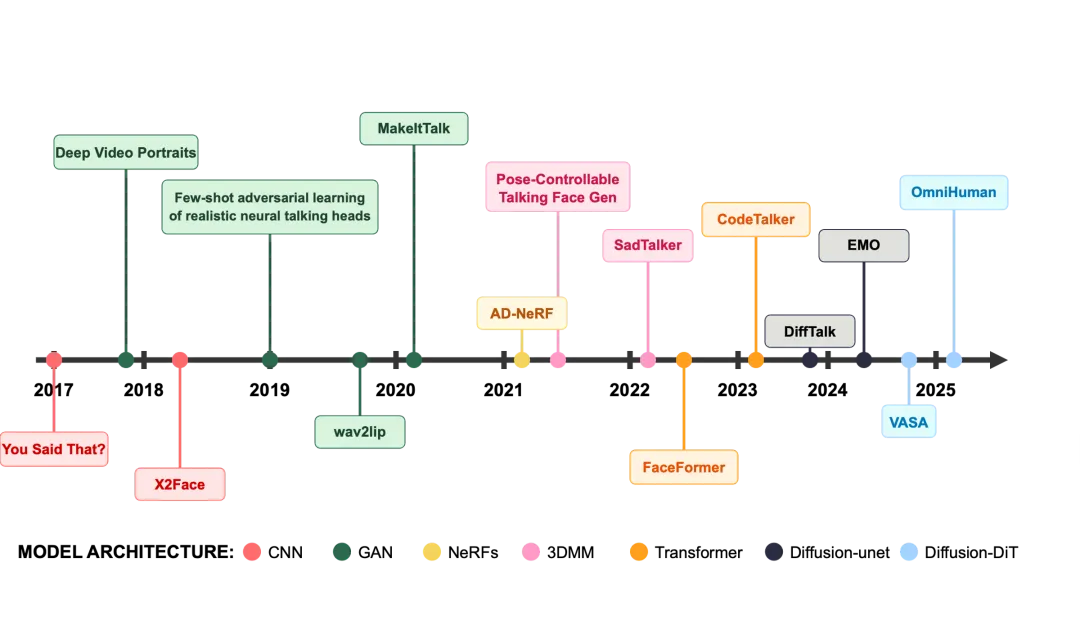
从”对口型”到”数字人” 音频驱动虚拟人合成技术全景解析
实时互动网
·

入选NeurIPS 2025,智源/北大/北邮提出多流控制视频生成框架,基于音频解混实现精确音画同步
HyperAI超神经
·

在线教程丨影视级视频生成模型Wan2.2-S2V-14B,仅需静态图和音频可生成分钟级数字人视频
HyperAI超神经
·
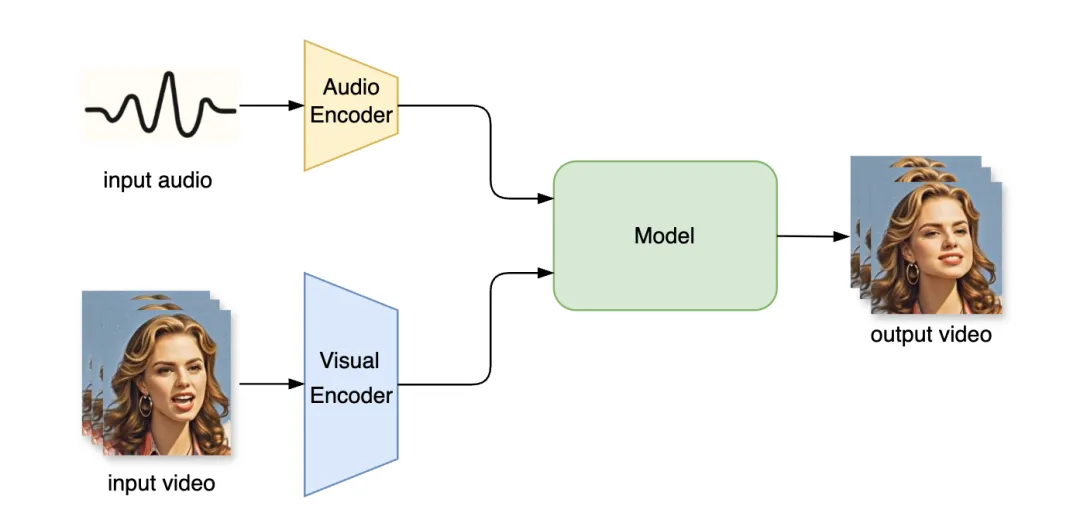
技术洞察:音频驱动口型生成技术解析 | 咪咕灯塔智库
实时互动网
·


