
技术洞察:音频驱动口型生成技术解析 | 咪咕灯塔智库
内容提要
在AIGC时代,音频驱动口型生成技术通过算法将音频信号转化为唇形动画,提升了数字人和影视动画的沉浸感,广泛应用于实时交互、游戏角色动态演绎及影视配音,重塑数字内容制作体验。
关键要点
-
在AIGC时代,音频驱动口型生成技术提升了数字人和影视动画的沉浸感。
-
音频驱动口型生成技术通过算法将音频信号转化为唇形动画,广泛应用于实时交互、游戏角色动态演绎及影视配音。
-
口型同步是提升用户体验的关键因素,传统方法效率低下,音频驱动技术解决了这一痛点。
-
音频驱动口型生成技术的核心目标是自动生成与音频匹配的角色唇形动画。
-
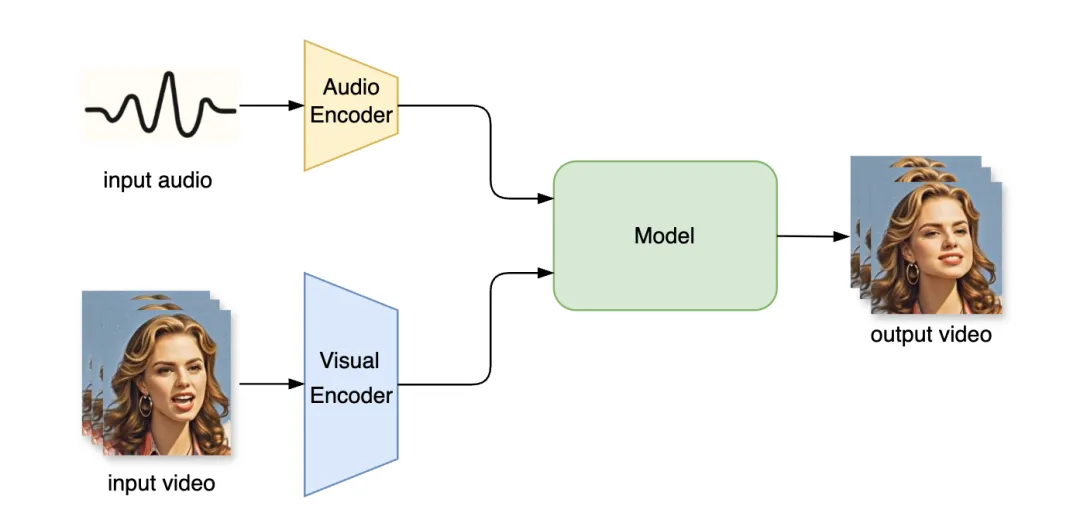
技术框架包括音频编码器、视觉编码器和生成模型,生成模型可采用GAN或扩散模型。
-
生成建模方法的挑战包括口型同步一致性和时序连贯性建模。
-
LatentSync和OmniSync是两种典型的音频驱动口型生成算法,分别采用隐空间扩散模型和无掩码方式。
-
音频驱动口型生成技术在在线客服、影视制作、游戏互动等多个领域展现出广阔的应用前景。
-
未来技术发展方向包括口型同步一致性、实时性和形态多样性等问题的持续改进。
延伸解读
技术背景与发展
音频驱动口型生成技术在AIGC时代的兴起,标志着数字人和影视动画行业的快速发展。传统的口型同步方法效率低下,依赖人工调整,而新技术通过算法实现自动化,显著提升了制作效率和用户体验。
应用场景与前景
该技术在在线客服、影视制作和游戏互动等领域展现出广阔的应用前景。随着技术的不断进步,未来可能在虚拟偶像表演和个人内容制作等新兴领域获得更大应用,推动数字内容创作的变革。
技术挑战与改进方向
尽管音频驱动口型生成技术取得了显著进展,但仍面临口型同步一致性和实时性等挑战。未来的研究将集中在提高生成质量、降低延迟和扩展应用场景,以满足不断提升的用户需求。
延伸问答
音频驱动口型生成技术的核心目标是什么?
音频驱动口型生成技术的核心目标是自动生成与音频匹配的角色唇形动画。
音频驱动口型生成技术在影视制作中有哪些应用?
该技术在影视制作中用于自动将音频信号转化为匹配的口型动画,提升制作效率,减少人工成本。
LatentSync和OmniSync有什么区别?
LatentSync使用隐空间扩散模型,强调口型同步一致性,而OmniSync则采用无掩码方式,增强鲁棒性和口型同步质量。
音频驱动口型生成技术如何提升用户体验?
通过实现口型与音频的精确同步,提升角色的自然表现,增强用户的沉浸感。
音频驱动口型生成技术面临哪些挑战?
主要挑战包括口型同步的一致性、时序连贯性建模和生成建模方法的稳定性。
未来音频驱动口型生成技术的发展方向是什么?
未来的发展方向包括提升口型同步一致性、实时性和形态多样性等问题的持续改进。
