

💡
原文中文,约5200字,阅读约需13分钟。
📝
内容提要
本文探讨了哔哩哔哩在视频生成模型优化方面的实践,重点介绍了分块自回归模型的计算与通信优化。通过引入因果注意力和KV缓存机制,Self-Forcing模型实现了更高效的视频生成,降低了延迟,并支持长视频生成和实时推理。
🎯
关键要点
- 本文探讨了哔哩哔哩在视频生成模型优化方面的实践。
- 重点介绍了分块自回归模型的计算与通信优化。
- Self-Forcing模型通过因果注意力和KV缓存机制实现高效视频生成。
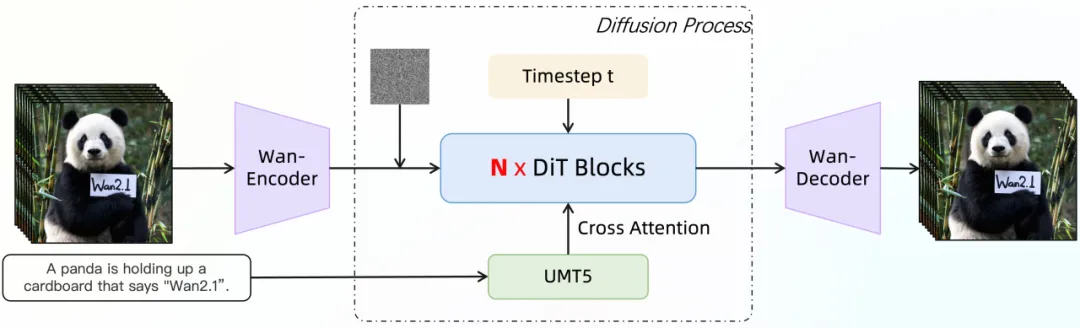
- Wan2.1是基于扩散Transformer架构的大规模视频生成基础模型。
- Wan2.1采用全时空并行建模思路,保证时序一致性。
- 全帧并行生成方式在长视频和实时推理场景中存在瓶颈。
- Self-Forcing模型通过因果生成重构视频扩散推理。
- Self-Forcing引入因果注意力约束,避免未来信息影响当前帧生成。
- 逐块生成策略支持任意长度视频生成,降低显存需求。
- Self-Forcing在生成质量上与Wan2.1持平,首帧延迟降低到亚秒级。
- 推理优化工作中引入序列并行支持,解决长视频推理瓶颈。
- RoPE计算逻辑优化,提升了整体推理性能。
- 通过预计算逻辑优化RoPE缓存,进一步提升计算性能。
➡️
