
用于大规模分布式AI训练的RoCE网络
内容提要
Meta在ACM SIGCOMM 2024会议上分享了他们在大规模分布式AI训练工作负载中使用的网络细节,包括采用RDMA over Ethernet技术构建数据中心网络、设计路径固定方案以提高网络流量均衡和路由效率、优化集体流量模式以改善网络拥塞控制。这些设计对分布式AI训练基础设施的发展至关重要。
关键要点
-
Meta在ACM SIGCOMM 2024会议上分享了大规模分布式AI训练工作负载的网络细节。
-
AI网络连接数万GPU,支持大规模模型训练。
-
Meta采用RDMA over Ethernet技术构建数据中心网络,优化了网络流量均衡和路由效率。
-
构建专用的后端网络以支持分布式训练,前端网络用于数据摄取和日志记录。
-
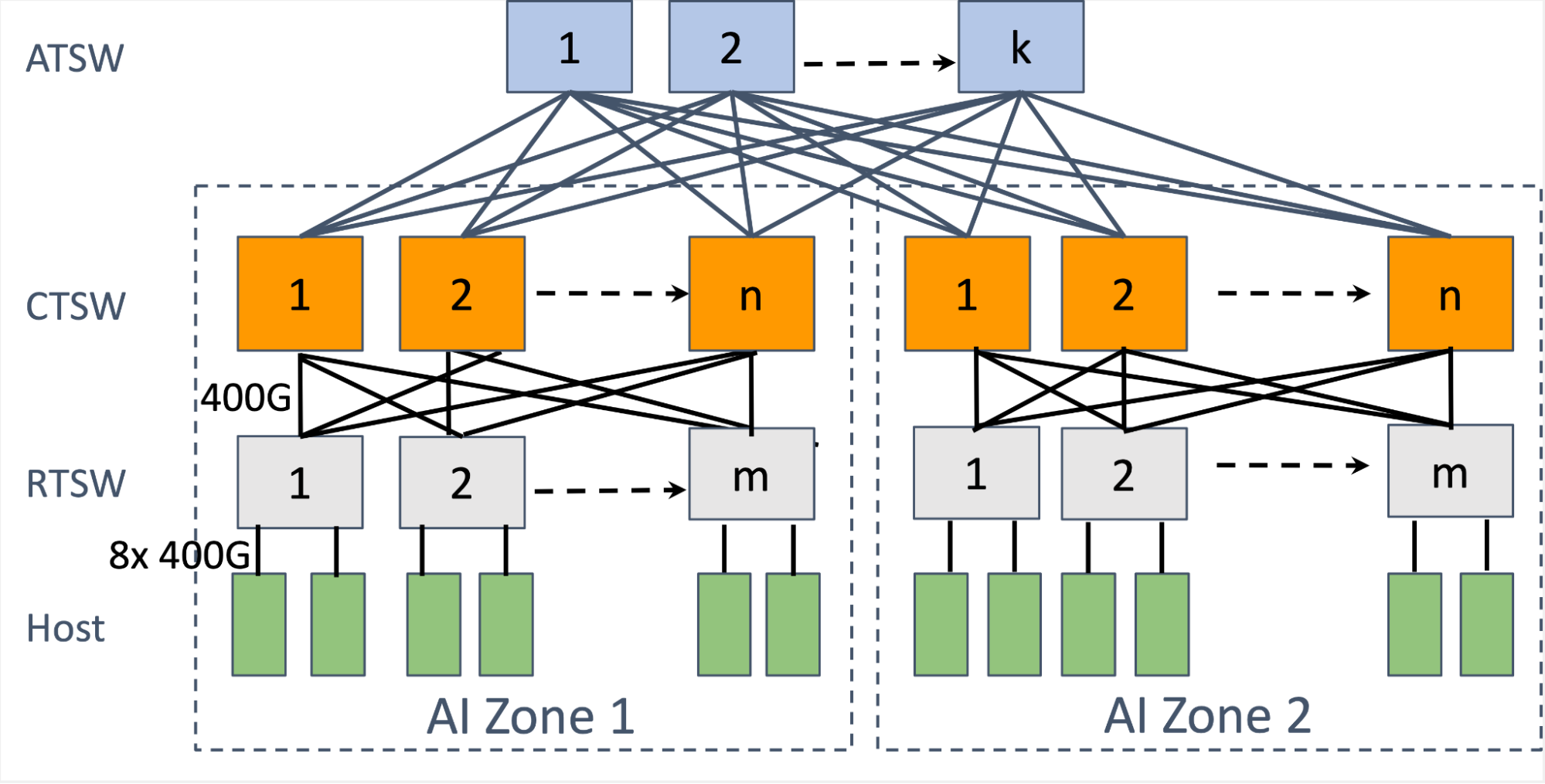
AI区采用两级Clos拓扑结构,支持大规模GPU互联。
-
为解决训练流量的低熵和突发性问题,Meta设计了路径固定方案。
-
通过增强的ECMP和队列对(QP)扩展,提高了网络流量的性能。
-
在400G部署中,Meta未使用DCQCN,而是依赖PFC进行流量控制。
-
接收驱动的流量接纳机制限制了网络中的在途流量,优化了性能。
-
Meta的网络基础设施将随着GenAI工作负载的快速增长而迅速演变。
延伸问答
Meta在大规模分布式AI训练中使用了什么网络技术?
Meta在大规模分布式AI训练中采用了RDMA over Ethernet(RoCEv2)技术。
Meta如何优化其AI训练网络的流量均衡?
Meta通过设计路径固定方案和增强的ECMP来优化网络流量均衡。
Meta的AI网络是如何支持大规模GPU互联的?
Meta的AI网络采用两级Clos拓扑结构,支持大规模GPU互联,确保高带宽和低延迟。
在400G部署中,Meta选择了什么样的流量控制方案?
在400G部署中,Meta未使用DCQCN,而是依赖PFC进行流量控制。
Meta是如何解决训练流量的低熵和突发性问题的?
Meta通过设计路径固定方案和优化训练作业调度器来解决训练流量的低熵和突发性问题。
Meta的网络基础设施将如何应对GenAI工作负载的增长?
Meta的网络基础设施将随着GenAI工作负载的快速增长而迅速演变,以满足日益增长的计算需求。
