
使用凝聚层次聚类进行嵌入聚类(杂乱文件夹整理AI)
内容提要
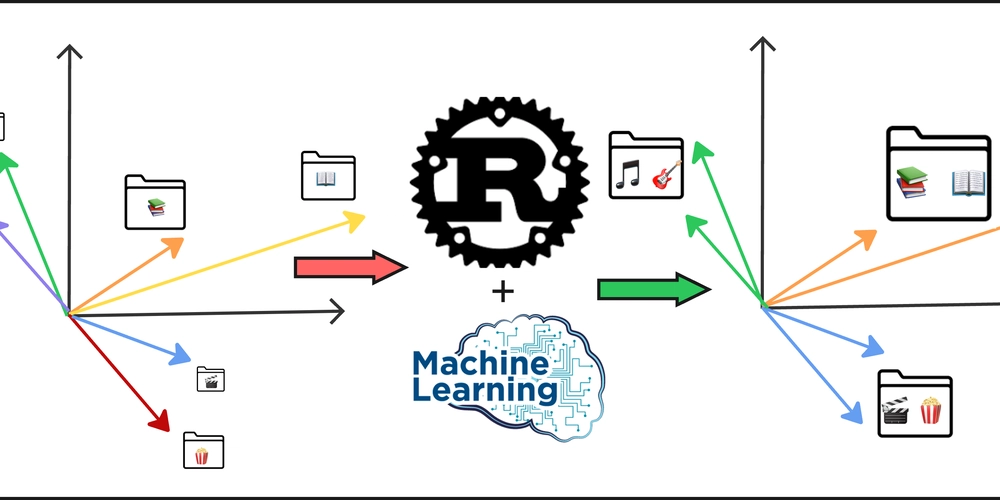
文章探讨了如何利用聚类算法(如凝聚层次聚类)整理杂乱文件夹。由于大型语言模型(LLM)存在上下文限制,无法一次处理大量文件名,因此需先进行聚类,以避免生成不相关的文件夹名称。选择凝聚层次聚类的原因包括无需预定义聚类数量和支持自定义距离度量。此外,文章强调了归一化和余弦距离在高维嵌入空间中的重要性。
关键要点
-
文章探讨了如何利用聚类算法整理杂乱文件夹。
-
大型语言模型(LLM)存在上下文限制,无法一次处理大量文件名。
-
选择凝聚层次聚类的原因包括无需预定义聚类数量和支持自定义距离度量。
-
归一化和余弦距离在高维嵌入空间中非常重要。
-
聚类算法的选择应考虑高维向量和相对较小的数据集。
-
凝聚层次聚类不需要预定义聚类数量,适合使用自定义距离度量。
-
归一化确保所有向量的单位长度,防止长度影响相似度。
-
余弦距离在高维嵌入空间中更能捕捉语义相似性。
-
聚合过程从每个嵌入作为独立聚类开始,逐步合并最近的聚类。
-
最终通过切割树状图决定提取的聚类数量,便于文件夹命名。
延伸解读
聚类算法的选择
在选择聚类算法时,需考虑数据的特性。凝聚层次聚类适合高维向量和相对较小的数据集,因其无需预定义聚类数量,且支持自定义距离度量。这使得它在处理复杂的文件名时,能够更好地捕捉语义相似性,避免生成不相关的文件夹名称。
归一化的重要性
归一化在聚类过程中至关重要,它确保所有向量的单位长度,从而防止长度对相似度的影响。特别是在使用余弦距离时,归一化能够更准确地反映向量之间的角度差异,提升聚类效果。
余弦距离的优势
在高维嵌入空间中,余弦距离比欧几里得距离更能有效捕捉语义相似性。尽管没有方法能完全避免维度诅咒,但余弦相似度在处理文本或语义数据时表现更为稳健,适合用于文件夹整理的场景。
延伸问答
为什么选择凝聚层次聚类来整理杂乱文件夹?
因为凝聚层次聚类无需预定义聚类数量,并支持自定义距离度量,适合处理高维嵌入空间。
归一化在聚类过程中有什么重要性?
归一化确保所有向量的单位长度,防止长度影响相似度,使余弦距离能准确反映角度差异。
余弦距离在高维嵌入空间中有什么优势?
余弦距离在高维空间中更能捕捉语义相似性,相较于欧几里得距离更稳定。
如何开始凝聚层次聚类的过程?
首先将每个嵌入视为独立聚类,然后逐步合并最近的聚类,直到只剩一个聚类或达到距离阈值。
聚类算法选择时需要考虑哪些因素?
需要考虑高维向量的特性和相对较小的数据集,以选择合适的聚类算法。
如何决定提取的聚类数量?
通过切割树状图,根据高度(距离)或所需的粒度来决定提取的聚类数量。
