

💡
原文中文,约6800字,阅读约需16分钟。
📝
内容提要
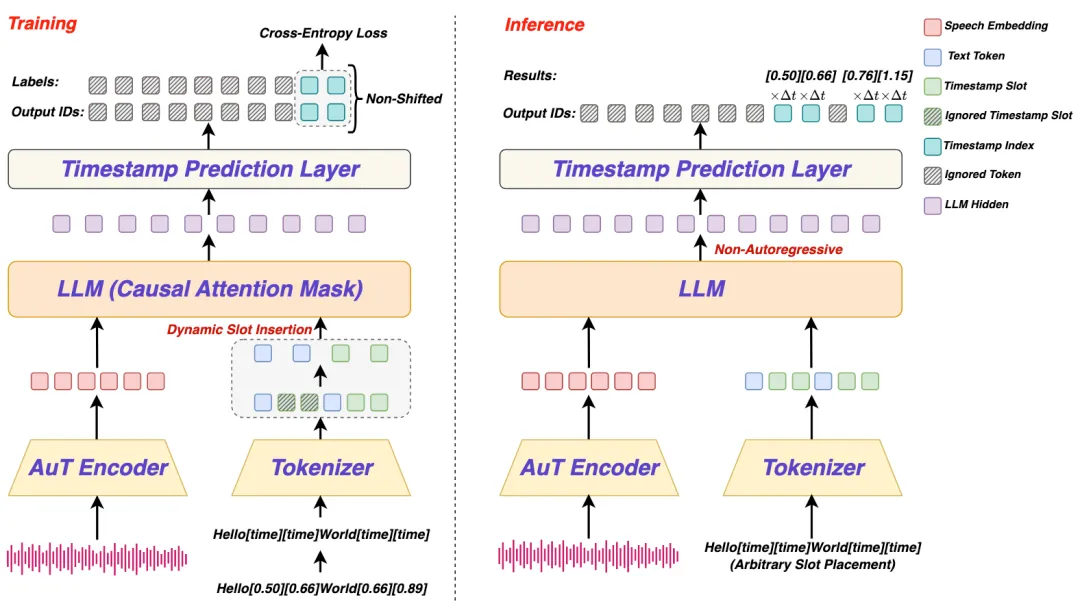
LLM-ForcedAligner是一种基于大语言模型的强制对齐方法,能够准确预测多语言语音的时间戳。该方法通过非自回归推理,解决了传统方法的时间偏移和计算速度慢的问题,支持最长5分钟的语音输入,并具备灵活的时间戳定义能力。实验结果表明,其在多语言场景下的表现优于其他方法。
🎯
关键要点
- LLM-ForcedAligner是一种基于大语言模型的强制对齐方法,能够准确预测多语言语音的时间戳。
- 该方法通过非自回归推理解决了传统方法的时间偏移和计算速度慢的问题。
- LLM-ForcedAligner支持最长5分钟的语音输入,并具备灵活的时间戳定义能力。
- 强制对齐在语音识别、自动字幕生成和语音分析等应用中至关重要。
- 现有的强制对齐方法主要分为传统混合系统和端到端模型,存在多语言处理的局限性。
- LLM-ForcedAligner采用槽位填充范式,直接预测词级或字符级的时间戳索引。
- 训练过程中使用MFA生成的伪时间戳标签,结合SLLM进行提炼和平滑处理。
- 该方法的多语言和跨语言能力由AuT语音编码器和多语言LLM共同提供。
- 实验结果显示,LLM-ForcedAligner在多语言场景下的表现优于其他方法,AAS相对降低了66%~73%。
- 动态槽位插入策略增强了模型的泛化能力,避免了过度依赖历史预测的时间戳。
- 选择合适的动态槽位插入比例对于提高模型性能至关重要。
🏷️
标签
➡️
