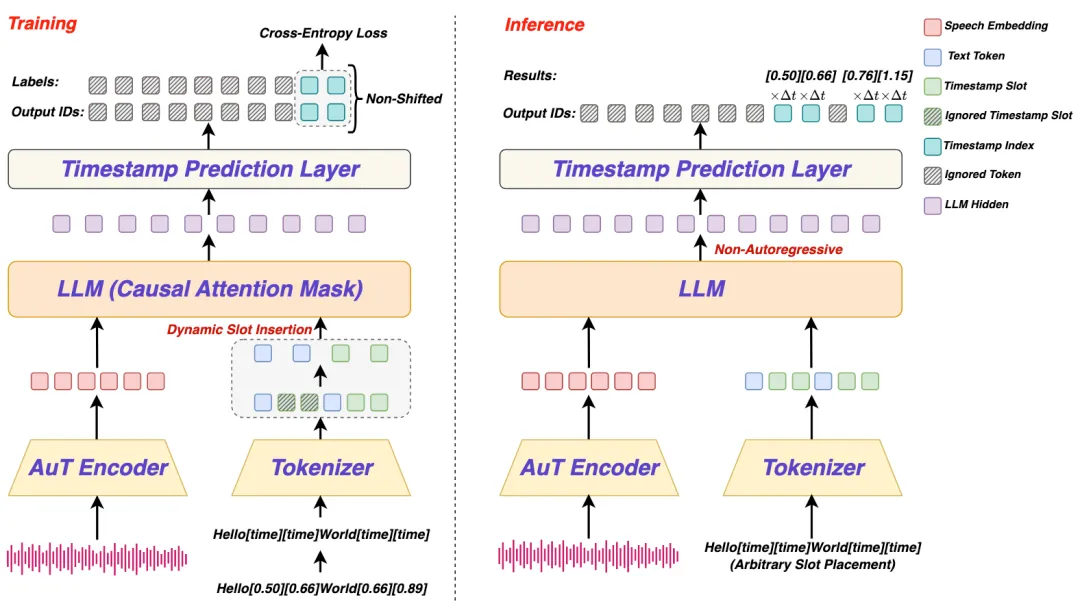
LLM-ForcedAligner是一种基于大语言模型的强制对齐方法,能够准确预测多语言语音的时间戳。该方法通过非自回归推理,解决了传统方法的时间偏移和计算速度慢的问题,支持最长5分钟的语音输入,并具备灵活的时间戳定义能力。实验结果表明,其在多语言场景下的表现优于其他方法。
Resemble AI 发布了开源的 Chatterbox-Turbo 对话式文本转语音模型,具备情绪控制功能,采用非自回归架构,显著提高生成速度和音质,适用于智能客服、游戏和教育等领域。
本文介绍了多种非自回归文本到语音(TTS)模型的创新,包括VARA-TTS、Diff-TTS和NAST-S2X。VARA-TTS通过多层注意力机制提高推理速度和语音质量,Diff-TTS显著提升合成速度,NAST-S2X实现高质量的同时口译。这些模型在推理效率和语音合成质量上均有显著进展。
Meissonic模型是一种非自回归的遮掩图像建模技术,用于高效的文本到图像合成。相比传统扩散模型,Meissonic通过架构创新和优化,实现高质量图像生成,展示了MIM技术的潜力。
本文介绍了一种新型语音识别架构——混合自回归推理转导器(HAINAN),通过非自回归生成初始假设,再用并行自回归细化,提高效率和准确性。实验显示,HAINAN在多语言数据集上表现优异,是实际应用的理想选择。
本研究提出了一种基于扩散的非自回归语言模型Diffusion-LM,能够有效执行复杂的可控生成任务,并在多个细粒度控制任务中表现出色。研究还探讨了数据增强、情感分析及扩散模型在自然语言处理中的应用,展示了其在生成和控制方面的优势。未来的研究将结合Transformers与扩散模型,以提升多模态能力。
本文介绍了一种非自回归流式Transformer(NAST),用于同时机器翻译(SiMT),通过新编码器和解码器降低延迟损失,实验证明其优于传统模型。此外,基于CTC的非自回归模型在语音翻译中显著提升了解码速度和翻译质量,展示了在多个基准测试中的优越性。
本文介绍了一种基于连接主义时间分类(CTC)的非自回归语音翻译模型,采用预测感知编码和跨层注意力方法,显著提高了解码速度和翻译质量。实验结果显示,该模型在多个基准测试中优于自回归模型,具有更高的BLEU分数和加速效果。
ProNet是一种新的深度学习方法,专为多时间段时间序列预测而设计。它自适应地融合了自回归和非自回归策略,使用潜在变量进行分段,通过变分推断有效地捕捉了各个时间步骤的重要性。相较于自回归模型,ProNet具有明显优势,可减少自回归迭代次数,预测速度更快,减少误差累积。与非自回归模型相比,ProNet提高了预测准确性。经过全面评估和消融研究,ProNet在准确性和预测速度上优于最先进的自回归和非自回归预测模型。
ProNet是一种新的深度学习方法,用于多时间段时间序列预测。它融合了自回归和非自回归策略,使用潜在变量进行分段,并通过变分推断捕捉各个时间步骤的重要性。ProNet比自回归模型更快,减少了误差累积,比非自回归模型更准确。经过评估和消融研究,ProNet优于最先进的预测模型。
本文提出了一种基于局部时空分离的Transformer块,用于视频未来帧预测,并构建了全自回归和非自回归视频预测Transformer框架。同时,引入对比特征损失来监督模型预测过程。该模型在性能上与更复杂的现有模型竞争力相当。
该论文提出了一种使用UMA的非自回归自动语音识别方法,可以缩短序列长度,降低识别错误和计算复杂度。实验证明UMA在非自回归方法中表现出优越或可比较的性能,并且通过将自条件CTC集成到该方法中,性能可以进一步提高。
完成下面两步后,将自动完成登录并继续当前操作。