
在Apache Spark™结构化流处理中引入更简便的变更数据捕获
内容提要
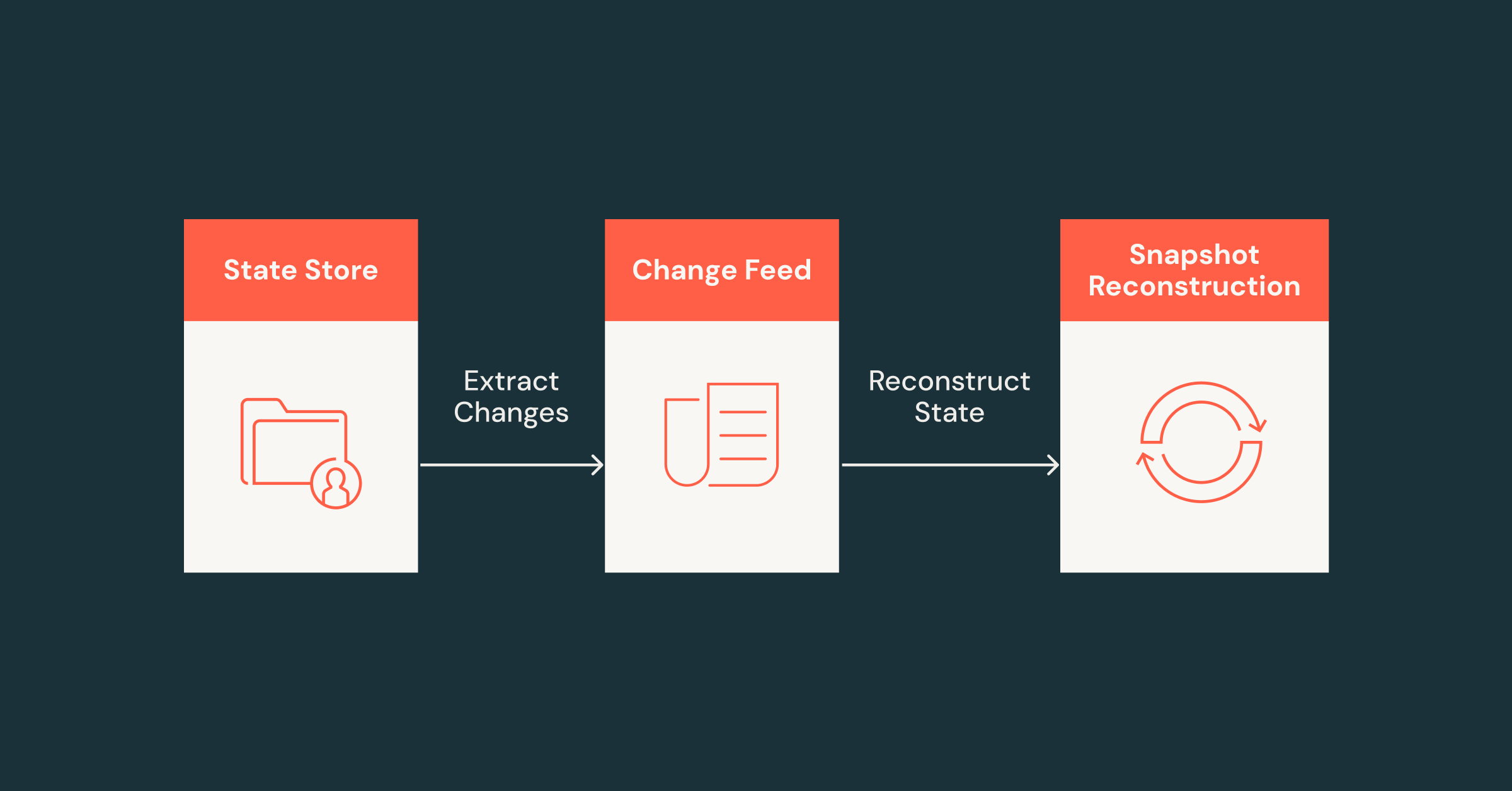
这篇博客介绍了Apache Spark™结构化流处理的新状态读取API的变更跟踪和快照功能,使用户能够更高效地访问和分析流处理的内部状态数据,简化调试和故障排除。新功能利用状态存储的变更日志数据,提供标准的变更数据捕获格式,并生成快照视图,帮助开发者和分析师更好地管理和可视化实时数据。
关键要点
-
这篇博客介绍了Apache Spark结构化流处理的新状态读取API的变更跟踪和快照功能。
-
新功能使用户能够更高效地访问和分析流处理的内部状态数据,简化调试和故障排除。
-
Databricks在2024年3月推出了状态读取API,旨在简化状态数据和元数据的查询。
-
状态读取API的新功能利用状态存储的变更日志数据,提供标准的变更数据捕获格式。
-
新功能生成快照视图,帮助开发者和分析师更好地管理和可视化实时数据。
-
状态读取API的变更跟踪功能加速了开发,简化了观察状态值变化的方法。
-
状态读取API的基本格式包括batchId、operatorId、storeName和joinSide等选项。
-
新选项包括变更读取、快照分区ID和快照开始批次ID等,简化了状态数据的查询。
-
快照功能可以帮助重建状态,避免因人为错误或bug导致的数据丢失。
-
新功能为审计、探索和可视化状态变化提供了新机会,帮助开发者和业务利益相关者获取有价值的见解。
延伸解读
新功能的实际应用
Apache Spark的状态读取API新功能不仅简化了开发过程,还为数据分析提供了便利。通过变更数据捕获格式,分析师可以更轻松地获取实时数据的变化,进而为业务决策提供支持。这种高效的数据访问方式将有助于提升数据驱动决策的速度和准确性。
变更跟踪的优势
新引入的变更跟踪功能使得开发者能够快速观察状态值的变化,减少了以往需要多次查询的繁琐过程。这一改进不仅加速了开发周期,还降低了调试和故障排除的复杂性,提升了整体工作效率。
快照功能的重要性
快照功能为状态重建提供了重要支持,尤其是在面对人为错误或系统故障时。通过生成快照,开发者可以有效避免数据丢失,确保系统的稳定性和可靠性。这一功能在数据管理和审计中具有重要的实用价值。
延伸问答
Apache Spark的状态读取API有什么新功能?
状态读取API引入了变更跟踪和快照功能,简化了状态数据的查询和分析。
如何使用状态读取API进行变更数据捕获?
通过设置变更读取选项为true,可以启用变更数据捕获,并指定开始和结束批次ID。
状态读取API的快照功能有什么用?
快照功能可以帮助重建状态,避免因错误或bug导致的数据丢失。
新API如何简化调试和故障排除?
新API通过提供变更跟踪和快照视图,使得观察状态变化和分析数据变得更加高效。
状态读取API的基本格式包括哪些选项?
基本格式包括batchId、operatorId、storeName和joinSide等选项。
新功能对数据分析师有什么帮助?
新功能使数据分析师能够更轻松地访问和可视化实时数据,促进数据的可操作性。
