
【Rust日报】2025-08-29 使用纯 Rust 实现 SIMD 加速算法(ChaCha20 / ChaCha12)的经验教训
内容提要
文章讨论了使用纯 Rust 实现 ChaCha20/ChaCha12 算法的 SIMD 加速经验,强调了并行化和数据块处理的加速思路。作者选择了 std::arch 原始 intrinsic 实现,认为 Rust 在不牺牲安全性的前提下,能够接近汇编性能,并期待 portable_simd 的稳定发布。
关键要点
-
文章讨论了使用纯 Rust 实现 ChaCha20/ChaCha12 算法的 SIMD 加速经验。
-
作者在 2 天内将算法提速到接近手写汇编水平,保持可读性和安全性。
-
SIMD 加速的三步曲为加载数据、并行计算和存储结果。
-
两种加速思路:算法并行化和将输入切成多个块并行处理。
-
选择指令集时,服务器使用 AVX-512,消费级机器优先 AVX2 + NEON。
-
实现方式对比:portable_simd、wide crate、pulp 和 std::arch 原始 intrinsic。
-
编译器自动向量化简单批量操作,通常无需手动写 intrinsics。
-
测试技巧包括使用 RUSTFLAGS 组合跑多套测试,GitHub Actions 暂不支持 AVX-512。
-
作者期待 nightly 的 portable_simd 稳定发布,降低维护量并提高性能。
-
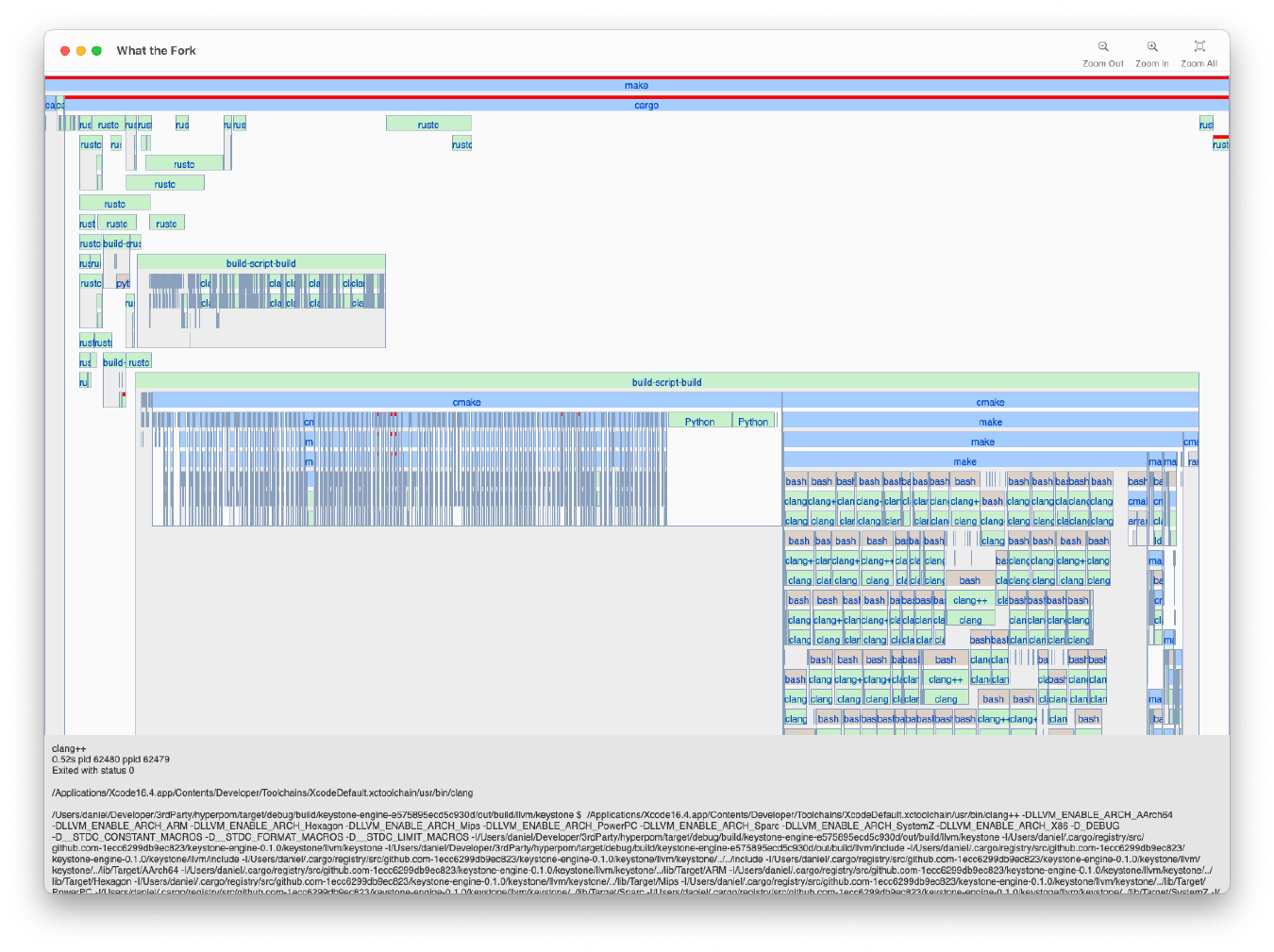
开发了 What the Fork 工具,用于分析和优化软件构建过程,支持多种构建系统和编程语言。
延伸解读
SIMD 加速的实现思路
文章中提到的两种加速思路分别是算法并行化和数据块并行处理。前者虽然复杂,但能在算法层面提升性能;后者则更易实现,适合大多数应用场景。开发者在选择时应根据具体需求和实现难度进行权衡。
指令集选择的重要性
选择合适的指令集对性能提升至关重要。文章建议服务器使用 AVX-512,而消费级机器则优先考虑 AVX2 和 NEON。开发者在编写代码时应考虑目标平台的特性,以确保代码在不同环境下的最佳性能。
编译器自动向量化的优势
文章指出,编译器通常能自动向量化简单的批量操作,开发者不必手动编写 intrinsics。这一特性降低了开发难度,同时也能在性能上获得显著提升,尤其是在处理简单的内存操作时。
未来的可移植性与维护性
作者对 nightly 的 portable_simd 表达了期待,认为其将显著降低代码维护量并提升性能。随着 Rust 生态的不断发展,开发者应关注这些新特性,以便在未来的项目中更好地利用 SIMD 加速。
延伸问答
如何使用纯 Rust 实现 ChaCha20/ChaCha12 算法的 SIMD 加速?
通过加载数据、并行计算和存储结果的三步曲来实现,保持代码的可读性和安全性。
在选择指令集时,Rust 开发者应该考虑哪些因素?
开发者应根据目标平台选择 AVX-512、AVX2 或 NEON,并使用运行时检测或编译时裁剪来优化性能。
作者在实现过程中遇到了哪些挑战?
作者面临的挑战包括保持代码的可读性和安全性,同时实现接近手写汇编的性能。
Rust 的 portable_simd 有什么优势?
它是跨平台的、无依赖的,未来将显著降低维护量并提高性能。
如何进行 SIMD 加速的测试?
可以使用 RUSTFLAGS 组合不同的测试,注意 GitHub Actions 暂不支持 AVX-512,需要在本地测试。
What the Fork 工具的功能是什么?
该工具用于分析和优化软件构建过程,支持多种构建系统和编程语言,帮助开发者发现构建瓶颈。
