
如何部署自然语言处理 (NLP):命名实体识别 (NER) 示例
内容提要
本文介绍了如何部署自然语言处理中的命名实体识别(NER)模型,包括选择模型、在Elasticsearch中部署、使用API进行实体提取,以及通过Ingest管道在文档采集时提取实体。以《悲惨世界》为例,展示了人名和地名的提取及结果可视化,同时讨论了模型性能优化的方法。
关键要点
-
本文介绍了如何部署命名实体识别(NER)模型,包括选择模型、在Elasticsearch中部署、使用API进行实体提取,以及通过Ingest管道提取实体。
-
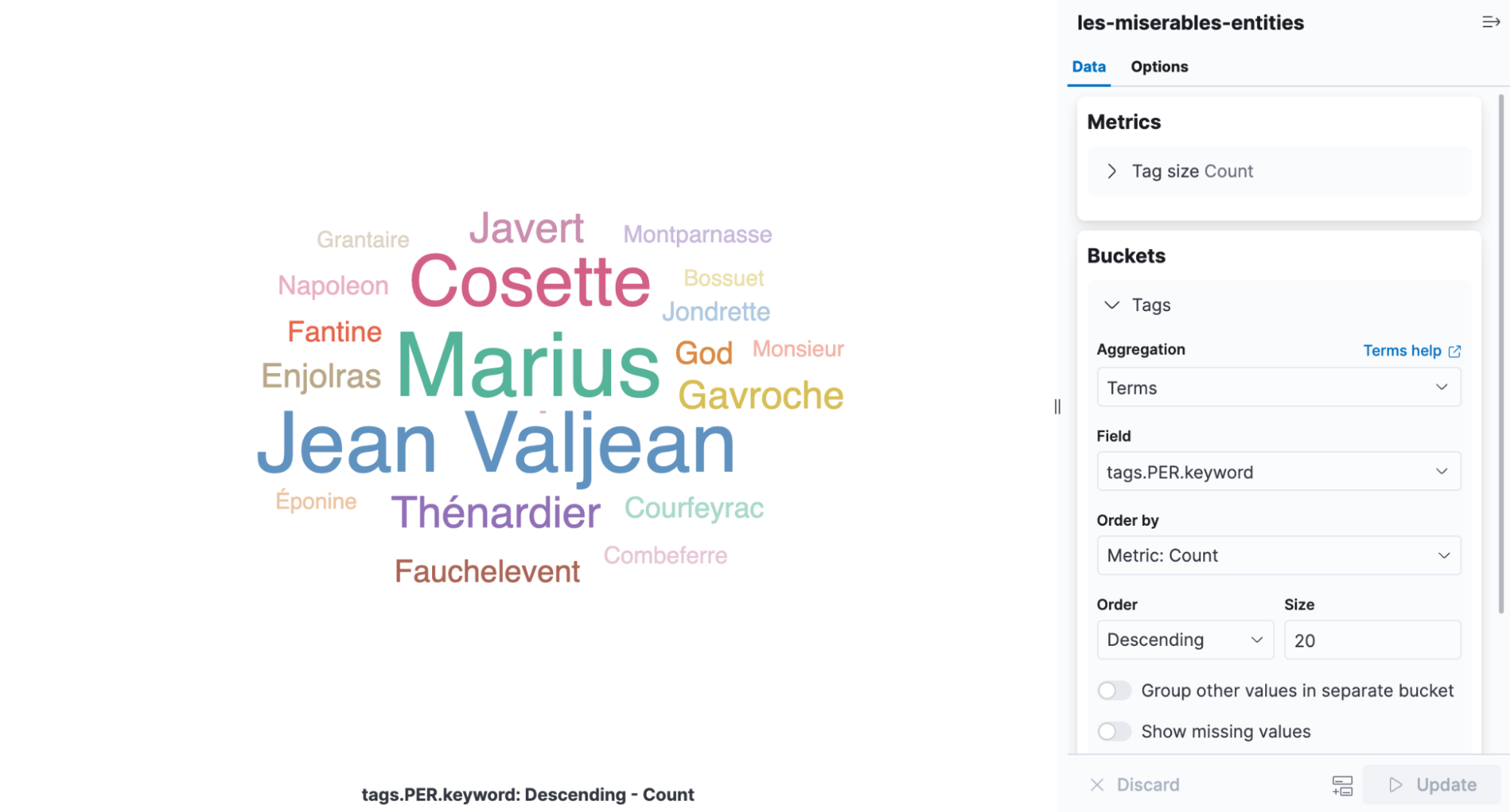
以《悲惨世界》为例,展示了如何提取人名和地名,并进行结果可视化。
-
选择NER模型时,可以从Hugging Face提供的多个模型中进行选择,并使用Eland安装模型。
-
通过新的_infer API可以测试已部署的NER模型,输入文本后模型会返回识别出的实体及其类别和置信度。
-
可以通过Ingest管道在文档采集时进行批量推理,并将提取的实体存储在Elasticsearch中。
-
在Kibana中创建标签云图可视化,展示在《悲惨世界》中提取到的人名频率。
-
通过调整推理线程和模型线程的设置,可以优化模型的推理性能,降低平均推理时间。
延伸解读
模型选择的重要性
在部署命名实体识别(NER)模型时,选择合适的模型至关重要。文章提到可以从Hugging Face提供的多个模型中进行选择,用户应根据具体需求和数据集特性来决定使用哪个模型。不同模型在性能和准确性上可能存在显著差异,因此在选择时需仔细评估。
优化推理性能的策略
文章中提到,通过调整推理线程和模型线程的设置,可以有效优化NER模型的推理性能。增加inference_threads可以缩短平均推理时间,而model_threads则有助于提高吞吐量。用户在实际应用中应根据系统负载和响应时间需求,灵活调整这些参数,以达到最佳性能。
批量推理的优势
使用Ingest管道进行批量推理可以在文档采集时自动提取实体,这一方法相比单次推理更为高效。文章强调,批量处理不仅能提高效率,还能将提取的实体直接存储在Elasticsearch中,便于后续分析和可视化。对于需要处理大量文本数据的场景,批量推理显得尤为重要。
延伸问答
如何选择合适的NER模型?
可以从Hugging Face提供的多个NER模型中进行选择,并使用Eland安装模型。
如何在Elasticsearch中部署NER模型?
通过Eland安装模型,并使用Docker命令将模型部署到Elasticsearch中。
如何使用API进行实体提取?
可以通过新的_infer API输入文本,模型会返回识别出的实体及其类别和置信度。
如何在文档采集时提取实体?
可以通过Ingest管道在文档采集时进行批量推理,并将提取的实体存储在Elasticsearch中。
如何优化NER模型的推理性能?
通过调整推理线程和模型线程的设置,可以优化模型的推理性能,降低平均推理时间。
如何可视化提取到的实体结果?
可以在Kibana中创建标签云图可视化,展示提取到的人名频率。
