该研究提出了一种构建微知识图谱的方法,解决了技术支持文档中实体和关系提取的粒度问题,从而提高了信息检索和推理的有效性。
本研究提出了一种新框架,结合MatSciBERT的实体提取模型与指针网络和注意力机制,从科学文献中提取多元组信息。实验结果表明,该模型在多个数据集上表现优异,有效支持材料设计和数据驱动创新。
txtai是一个嵌入数据库,适用于语义搜索和语言模型工作流。本文探讨如何利用txtai构建天文学知识图谱,整合维基百科信息,提取恒星、行星和星系等实体,以提高检索和生成的准确性与速度。
本研究提出了Graphusion框架,旨在解决知识图谱构建中的局部视角问题。通过零-shot方法从自由文本中构建知识图谱,并设计了融合模块,以提高实体提取和关系识别的准确性,展示了在教育场景中的应用潜力。
本文研究了基础LLM和专门的预训练模型在实体和关系提取方面的应用。实验结果表明,使用先进的LLM模型可以提高从非结构化文本创建知识图谱的准确性,并探索了使用LLM模型自动创建本体论的潜力,取得更相关和准确的知识图谱。
该研究使用大语言模型(LLMs)从网络安全文本中提取实体,以识别发展趋势和监测新兴趋势。研究发现LLMs的知识实体并不完全反映网络安全的上下文,但名词提取器在此领域具有潜力。通过统计分析,开发了一种名词提取器,可从领域中提取特定且相关的复合名词。测试结果显示该模型在LLM领域中识别趋势存在一些限制,但仍能提供有关新兴趋势演变的有希望的结果。
该研究利用多模态提取和图像文本对齐,采用创新的预训练目标来提高实体和关系的提取能力。实验结果表明,相对于先前的最佳方法,该方法的F1值提高了3.41%,并且对先前的多模态融合技术是正交的。在先前的最佳方法的基础上,该方法提高了5.47%的F1。
本文研究了使用LLM模型在可持续发展文本中进行实体和关系提取的应用,结果表明使用LLM模型可以提高知识图谱的准确性,并探索了使用基础LLM模型自动创建本体论的潜力。
本文比较了基础LLM(ChatGPT)和专门的预训练模型(REBEL)在联合实体和关系提取中的性能。实验结果表明,使用先进的LLM模型可以提高从非结构化文本创建知识图谱的准确性。同时,还探索了使用基础LLM模型自动创建本体论的潜力,以获得更相关和准确的知识图谱。
本文分析了基础LLM(ChatGPT)和专门的预训练模型(REBEL)在联合实体和关系提取应用中的表现。结果显示使用先进的LLM模型可以提高从非结构化文本创建知识图谱的准确性。同时,还探索了使用基础LLM模型自动创建本体论的潜力,以获得更相关和准确的知识图谱。
本文比较了基础LLM和专门的预训练模型在联合实体和关系提取方面的表现。实验结果显示,使用先进的LLM模型可以提高从非结构化文本创建知识图谱的准确性。同时,还探索了使用基础LLM模型自动创建本体论的潜力,以获得更相关和准确的知识图谱。
本文介绍了 Rasa NLU 的重要组件,包括语言模型、分词组件、特征提取组件、意图分类组件和实体提取器。推荐使用 SpacyNLP 作为语言模型,分词组件可选 JiebaTokenizer、MitieTokenizer 或 SpacyTokenizer。特征提取组件可使用 RegexFeaturizer 等多个组件。意图分类组件包括 MitieIntentClassifier、LogisticRegressionClassifier、SklearnIntentClassifier、KeywordIntentClassifier、DIETClassifier 和 FallbackClassifier。nlu.yml 是训练数据,可用于智能识别意图。
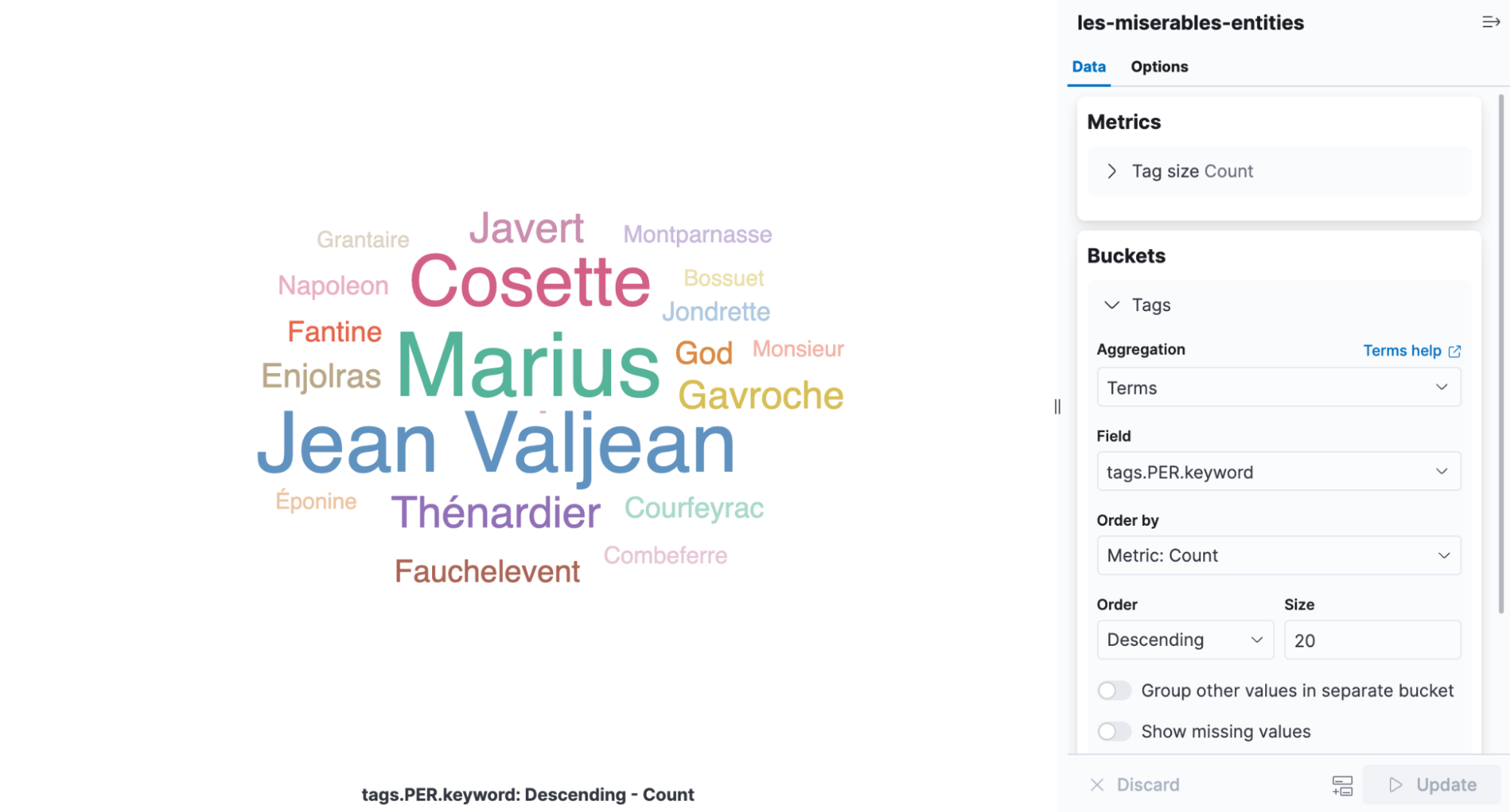
本文介绍了如何部署自然语言处理中的命名实体识别(NER)模型,包括选择模型、在Elasticsearch中部署、使用API进行实体提取,以及通过Ingest管道在文档采集时提取实体。以《悲惨世界》为例,展示了人名和地名的提取及结果可视化,同时讨论了模型性能优化的方法。
完成下面两步后,将自动完成登录并继续当前操作。