
ChatGPT的自动优化
原文中文,约20100字,阅读约需48分钟。
📝
内容提要
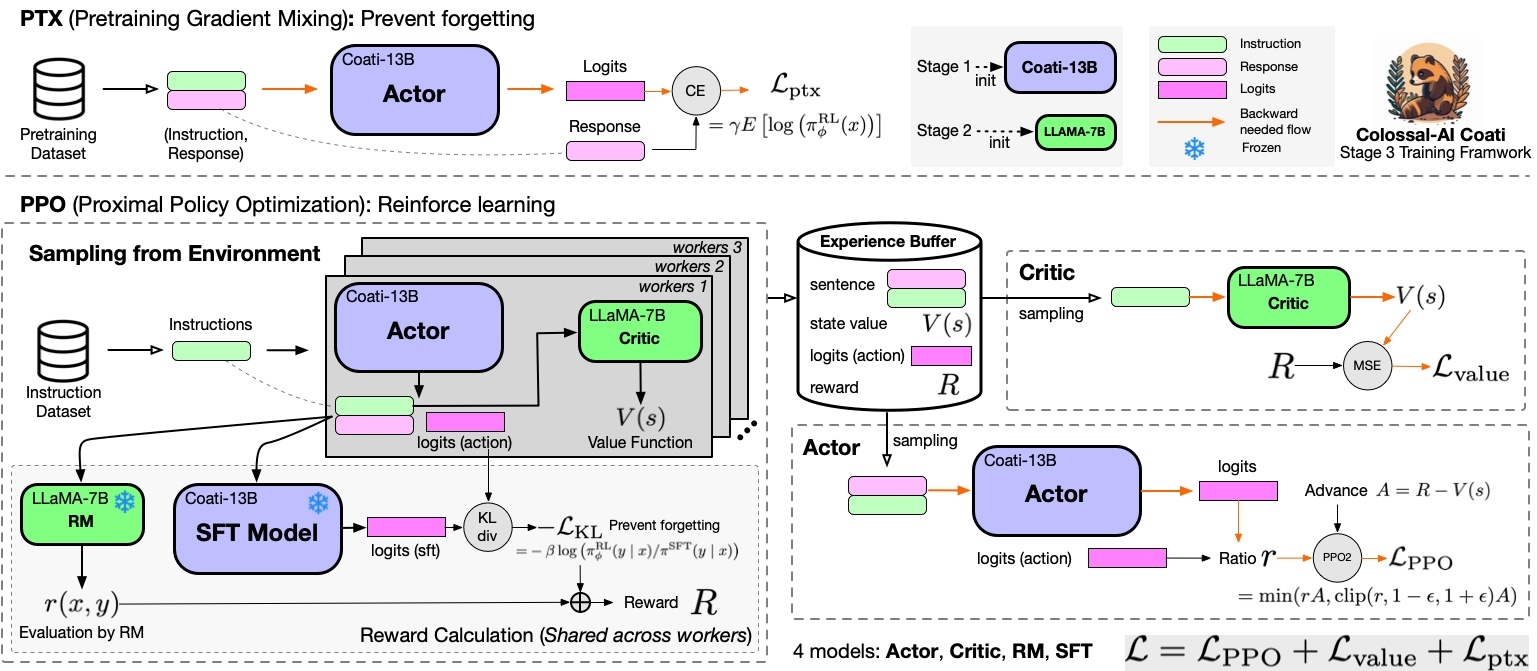
本文介绍了强化学习在ChatGPT模型中的应用,强化学习是一种通过智能体与环境交互学习策略的机器学习方法。在ChatGPT中,使用了PPO和Actor-Critic算法的组合来优化模型,通过RLHF算法实现自动优化。
🎯
关键要点
-
强化学习是一种通过智能体与环境交互学习策略的机器学习方法。
-
ChatGPT使用PPO和Actor-Critic算法的组合来优化模型。
-
强化学习的基本要素包括智能体、环境、状态、动作和奖励。
-
在ChatGPT中,模型作为智能体,环境是对话系统,状态是对话上下文,动作是选择回复,奖励是人类反馈的质量。
-
常见的强化学习算法包括Q-learning、SARSA、DQN、Policy Gradient、PPO和Actor-Critic。
-
RLHF算法结合了PPO和Actor-Critic的优势,实现了高效稳定的模型优化。
-
代码示例展示了如何使用PyTorch实现策略梯度算法和Actor-Critic算法。
-
KL散度用于衡量生成模型与真实数据分布之间的差异,帮助调整奖励信号。
-
RLHF算法允许模型在没有人类参与的情况下自动优化,提升ChatGPT的智能回复能力。
-
理解机器学习技术的原理有助于形成对其理性的认知。
🏷️
