
Meta AI 推出感知编码器:一款大规模视觉编码器,在图像和视频的多项视觉任务中表现出色
内容提要
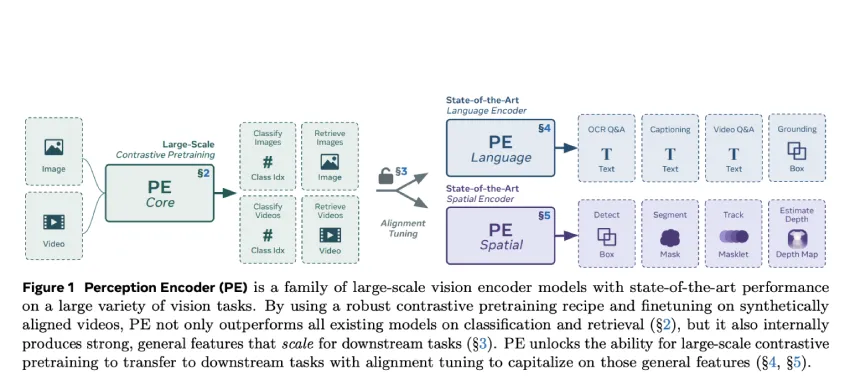
Meta AI推出的感知编码器(PE)通过单一对比学习目标,构建了一个通用视觉编码器,支持多种视觉任务,如图像和视频分类、检索等,展现出强大的零样本泛化能力,为多模态AI系统奠定了高效基础。
关键要点
-
Meta AI推出感知编码器(PE),构建通用视觉编码器,支持多种视觉任务。
-
视觉编码器需识别物体、场景,并支持字幕制作、问答等复杂任务。
-
现有模型依赖多种预训练目标,导致可扩展性和部署复杂。
-
PE采用单一对比学习目标,摒弃传统多目标预训练范式。
-
PE涵盖三个尺度,最大模型包含2B个参数,表现出色。
-
PE的预训练分为两个阶段,第一阶段为鲁棒对比学习,第二阶段为视频理解。
-
PE在视觉基准测试中展现强大的零样本泛化能力,分类性能优越。
-
视频任务中,PE在零样本分类和检索基准上表现最佳。
-
PE提供了构建通用视觉编码器的技术证明,采用统一且可扩展的方法。
-
PE及其代码库和数据集为多模态AI系统提供高效基础。
延伸解读
感知编码器的创新之处
Meta AI的感知编码器(PE)通过单一对比学习目标,简化了视觉编码器的训练过程。这种方法不仅提高了模型的可扩展性,还减少了传统多目标预训练带来的复杂性,使得在多模态任务中表现更为出色。
零样本泛化能力的重要性
PE在视觉基准测试中展现出强大的零样本泛化能力,这意味着它能够在未见过的数据上依然保持高性能。这一特性对于实际应用至关重要,尤其是在数据稀缺或标注成本高昂的场景中,能够显著降低对大量标注数据的依赖。
多模态AI系统的基础
PE的发布为构建多模态AI系统提供了高效的基础。其统一且可扩展的方法,结合强大的视觉理解能力,能够支持更复杂的任务,如视频理解和跨模态推理,推动AI技术的进一步发展。
延伸问答
感知编码器(PE)有什么主要功能?
感知编码器(PE)支持多种视觉任务,如图像和视频分类、检索等,展现出强大的零样本泛化能力。
感知编码器是如何训练的?
PE的预训练分为两个阶段,第一阶段为鲁棒对比学习,第二阶段为视频理解,使用大规模图文数据集和视频数据引擎。
感知编码器与传统模型相比有什么优势?
PE采用单一对比学习目标,摒弃多目标预训练范式,简化了模型的可扩展性和部署。
感知编码器在视觉基准测试中的表现如何?
PE在视觉基准测试中展现出强大的零样本泛化能力,分类性能优越,甚至超越了在大型私有数据集上训练的专有模型。
感知编码器的参数规模有多大?
感知编码器涵盖三个尺度,其中最大的模型包含2B个参数。
感知编码器如何支持多模态AI系统?
PE及其代码库和数据集为多模态AI系统提供高效基础,允许研究者构建可重复的视觉理解模型。
