
Zyphra发布Zamba2-VL:混合Mamba2-Transformer视觉语言模型
内容提要
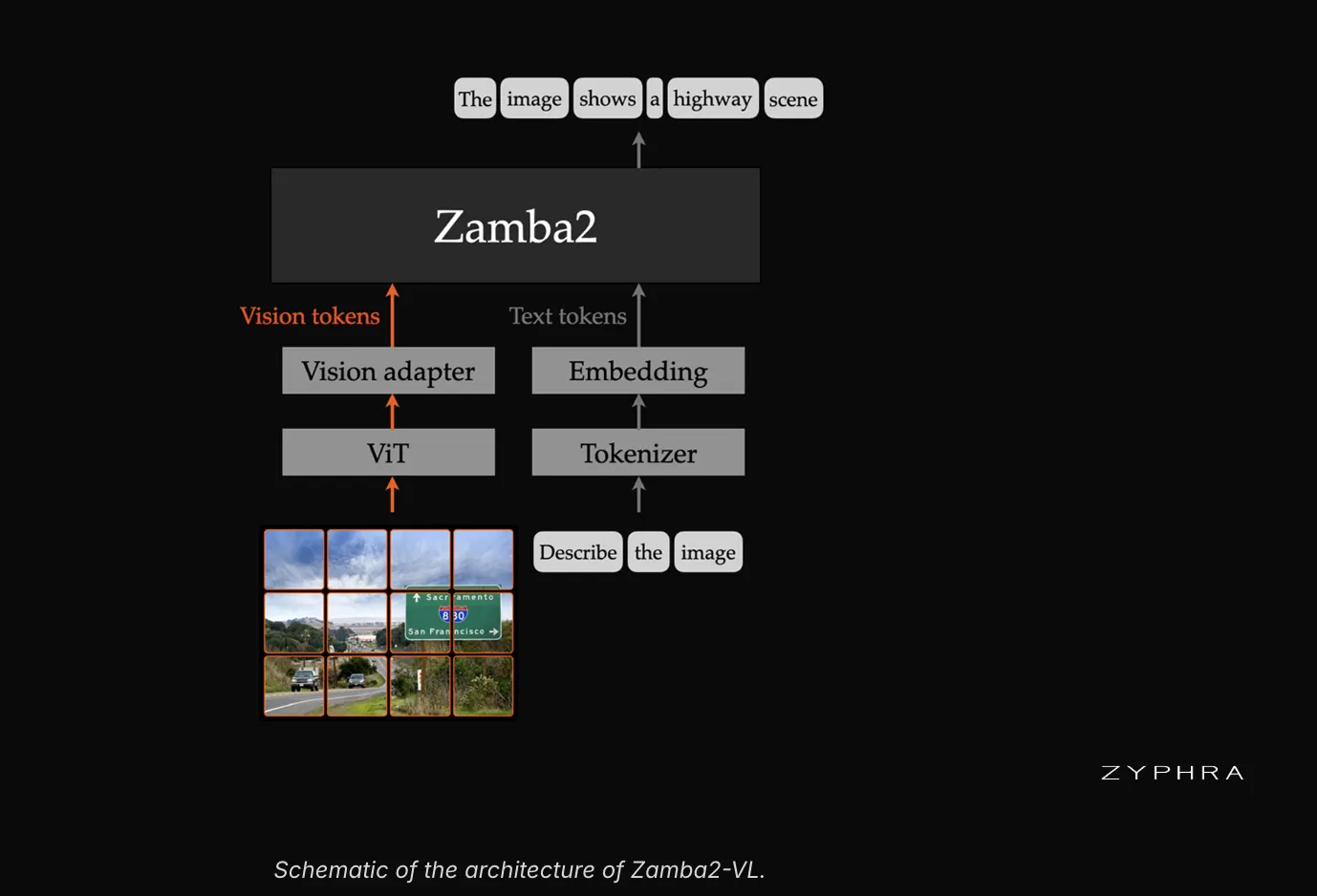
Zyphra发布了Zamba2-VL系列开放视觉语言模型,包含12亿、27亿和70亿参数。该模型采用混合SSM-Transformer架构,支持图像与文本的理解与关联,推理速度快,适用于文档提取和库存盘点等场景。尽管在知识推理方面表现不如大型模型,但在视觉计数和文档理解上具有优势。模型权重和推理代码已公开。
关键要点
-
Zyphra发布了Zamba2-VL系列开放视觉语言模型,包含12亿、27亿和70亿参数。
-
Zamba2-VL采用混合SSM-Transformer架构,支持图像与文本的理解与关联。
-
该模型在视觉计数和文档理解上表现优异,但在知识推理方面不如大型模型。
-
Zamba2-VL的推理速度快,适用于文档提取和库存盘点等场景。
-
模型权重和推理代码已公开,采用Apache 2.0许可证。
延伸解读
Zamba2-VL的应用场景
Zamba2-VL在文档提取和库存盘点等实际应用中表现出色,尤其适合处理发票解析和收据数字化等任务。其强大的视觉计数能力使其在零售环境中尤为有用,能够快速处理大量图像数据。
模型的优势与局限
尽管Zamba2-VL在视觉计数和文档理解方面表现优异,但在知识推理能力上仍落后于一些大型模型,如MMMU和MathVista。这意味着在需要深度推理的应用场景中,用户可能需要考虑其他更强大的模型。
推理速度的优势
Zamba2-VL的推理速度显著优于传统的Transformer模型,尤其是在处理高分辨率图像时。其近乎线性的预填充机制使得在设备端和边缘计算中具有更好的应用前景,适合实时处理需求。
延伸问答
Zamba2-VL模型的参数规模有哪些?
Zamba2-VL模型包含12亿、27亿和70亿参数。
Zamba2-VL采用了什么样的架构?
Zamba2-VL采用混合SSM-Transformer架构。
Zamba2-VL在视觉计数和文档理解方面的表现如何?
Zamba2-VL在视觉计数和文档理解上表现优异,但在知识推理方面不如大型模型。
Zamba2-VL适用于哪些应用场景?
Zamba2-VL适用于文档提取、库存盘点等场景。
Zamba2-VL的推理速度有什么优势?
Zamba2-VL的推理速度快,避免了注意力机制中键值缓存的增长,具有近乎线性的预填充机制。
Zamba2-VL的模型权重和推理代码在哪里可以找到?
Zamba2-VL的模型权重和推理代码已在Hugging Face和GitHub上公开。
