

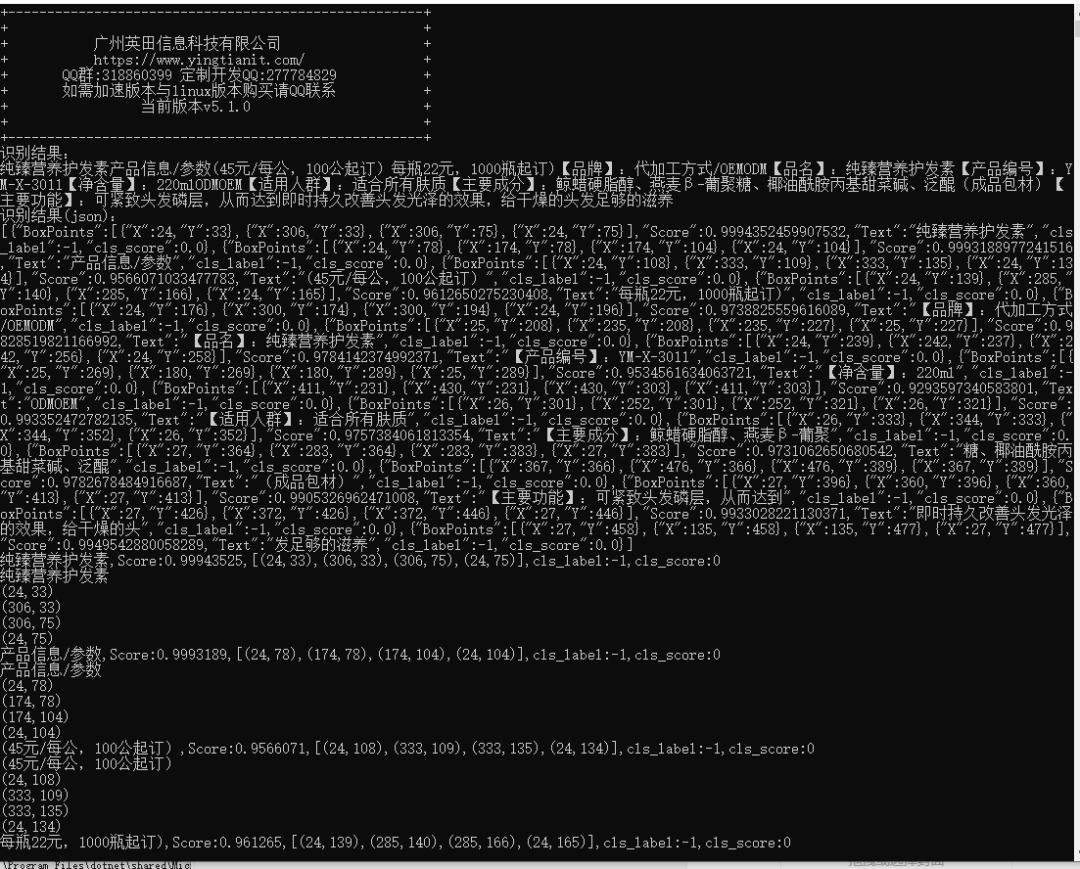
PaddleOCRSharp如何加载自己的模型
💡
原文中文,约7800字,阅读约需19分钟。
📝
内容提要
PaddleOCRSharp 是一个基于百度飞桨的 C# OCR 识别库,适合.NET 开发者。它支持中、英等多语言识别,并允许自定义模型以优化特定场景的识别效果。使用前需配置开发环境并确保模型格式正确,开发者可通过调整配置和编写代码快速实现 OCR 识别。
🎯
关键要点
- PaddleOCRSharp 是基于百度飞桨的 C# OCR 识别库,适合.NET 开发者。
- 支持中、英等多语言识别,并允许自定义模型以优化特定场景的识别效果。
- 使用前需配置开发环境,确保模型格式正确。
- 开发环境要求包括.NET Framework 4.0 及以上或.NET Core 6.0以上,Windows 操作系统。
- 自定义模型需满足特定格式要求,包括检测模型、识别模型和可选的方向分类模型。
- 项目目录规划建议按分类存放模型,避免文件路径混乱。
- 加载自定义模型的核心逻辑是通过配置类指定模型路径和字典,而非修改源码。
- 项目发布时需确保模型文件和运行库完整,运行时可直接查看识别结果。
- 在 WinForm/WPF 项目中使用自定义模型时,核心配置与控制台项目一致。
- 常见问题包括模型文件不存在、识别结果乱码、CPU 推理速度慢等,需进行相应排查。
- 进阶优化建议包括增加场景化样本、调整检测阈值、使用单例模式提升效率。
- PaddleOCRSharp 的高扩展性使其成为.NET 开发者实现定制化 OCR 需求的优质选择。
🏷️
标签
➡️
