
C++ vs .NET 数组原地反转实测:小数组 C++ 碾压,大数组 .NET 反杀?
内容提要
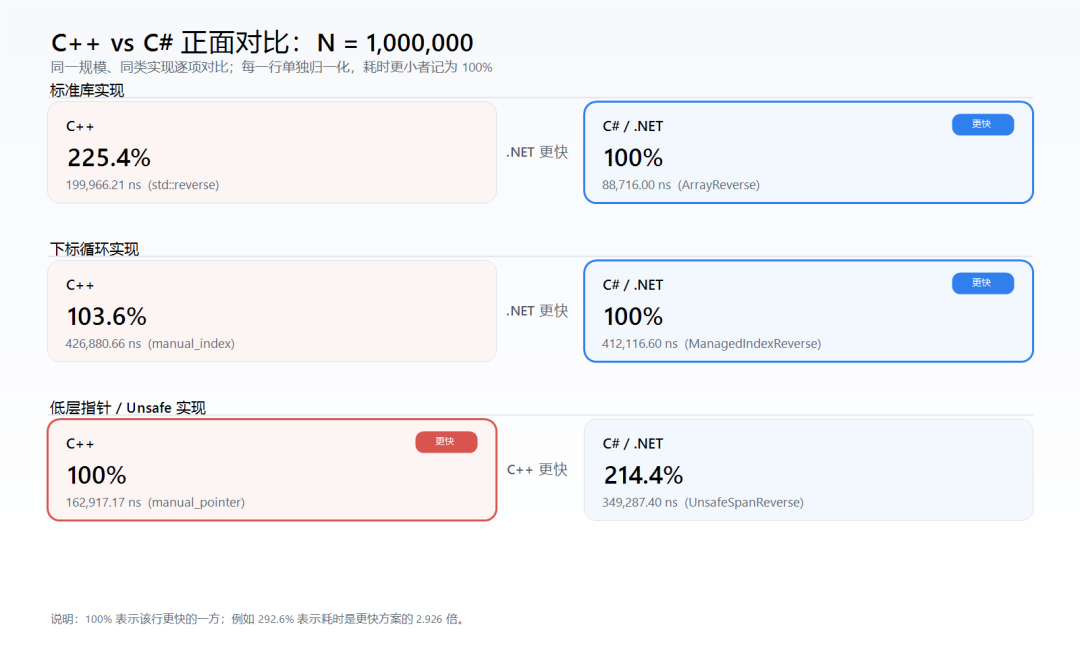
在数组原地反转性能对比中,小数组时C++表现优异,而大数组时.NET的Array.Reverse反超。经过控制变量测试,结果显示C++在小规模时更快,.NET在大规模时更具优势,反映出两者在不同场景下的性能特点。
关键要点
-
C++在小数组(1000个元素)下性能优于.NET,而在大数组(1000000个元素)时.NET的Array.Reverse表现更好。
-
原文章的对比没有控制好变量,C#测试的是原地反转,而C++使用了std::reverse_copy,导致不公平。
-
为了公平测试,重新制定了测试规则,确保双方都只进行纯原地反转操作。
-
测试结果显示,C++在小数组时的性能优势明显,而在大数组时.NET的Array.Reverse吞吐量更高。
-
小数组场景中,C++的指针操作开销小,编译器优化到极致,而.NET的固定成本导致性能略逊。
-
大数组场景中,.NET的Array.Reverse针对基元类型进行了深度优化,展现出更高的吞吐量。
-
测试数据表明,手写算法不一定优于标准库,标准库的优化通常更为强大。
-
性能分析需要考虑具体场景,C++和.NET各有优势,不能简单比较。
延伸解读
小数组与大数组的性能差异
在小数组的测试中,C++由于其指针操作的低开销和编译器的优化,表现出色。然而,当数据量增大到100万时,.NET的Array.Reverse展现出更高的吞吐量。这表明在不同规模的数据处理上,选择合适的编程语言和方法至关重要。
控制变量的重要性
原文章的对比未能控制变量,导致C++和.NET的性能比较不公平。通过确保两者都进行纯原地反转操作,测试结果更具参考价值。这提醒开发者在性能测试时,必须严格控制实验条件,以获得准确的结论。
标准库的优势
测试结果显示,手写算法不一定优于标准库,.NET的Array.Reverse在大数据量下的表现优于手写的Unsafe代码。这强调了使用标准库的优势,开发者在追求性能时应优先考虑经过优化的库函数,而非盲目实现自定义算法。
延伸问答
C++和.NET在小数组反转性能上有什么区别?
C++在小数组(1000个元素)时表现优异,速度明显快于.NET的Array.Reverse。
在大数组反转时,为什么.NET的表现更好?
.NET的Array.Reverse在大数组(1000000个元素)时展现出更高的吞吐量,主要因为其针对基元类型进行了深度优化。
原文章的对比测试存在哪些问题?
原文章未控制变量,C#测试的是原地反转,而C++使用了std::reverse_copy,导致不公平的比较。
如何进行公平的数组反转性能测试?
公平测试需确保双方只进行纯原地反转操作,并控制状态污染和消除死代码。
C++和.NET的标准库在性能上有什么差异?
C++的标准库在小规模操作中表现出色,而.NET的标准库在大规模数据处理时优化更为强大。
为什么手写算法不一定优于标准库?
测试数据表明,标准库的优化通常更为强大,手写算法可能在性能上不如官方实现。
