
Meta提出AI数据科学家,Autodata构建高质量训练/评测数据集
内容提要
近年来,人工智能的发展逐渐从算法创新转向数据质量驱动。合成数据成为重要支撑,Meta的Autodata框架通过智能体模拟数据科学家,生成高质量训练数据,显著提升模型性能,展示了合成数据生成的新范式。
关键要点
-
近年来,人工智能的发展逐渐从算法创新转向数据质量驱动。
-
合成数据成为后训练阶段的重要支撑方式,能够生成稀缺的边缘案例与长尾场景。
-
Meta的Autodata框架通过智能体模拟数据科学家,生成高质量训练数据。
-
Autodata框架包含数据生成、数据分析和整体循环,旨在不断提升数据质量。
-
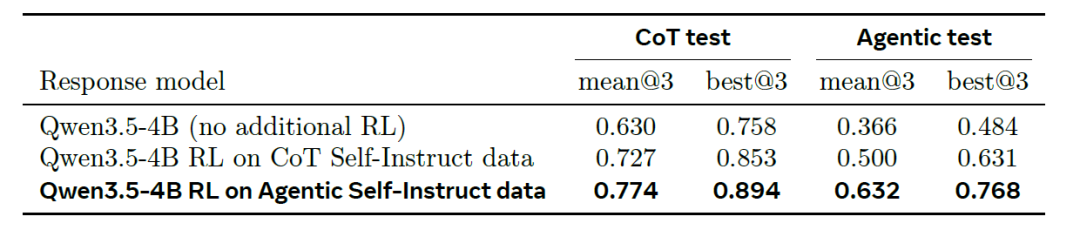
研究表明,使用Agentic Self-Instruct生成的数据在多个任务上显著提升了模型性能。
-
Autodata框架在计算机科学、法律推理和科学推理任务中均表现出优越性。
-
该研究为未来AI发展提供了新的数据生成范式,具有广泛的应用潜力。
延伸解读
合成数据的优势与挑战
合成数据在人工智能训练中的重要性日益凸显,尤其是在高质量标注数据稀缺的情况下。它能够生成边缘案例和长尾场景,降低人工标注的成本和时间。然而,合成数据的质量控制仍然是一个挑战,如何确保生成数据的多样性和准确性是未来研究的关键。
Autodata框架的创新性
Meta的Autodata框架通过模拟数据科学家的智能体,提供了一种新的数据生成方法。这种方法不仅提高了数据质量,还通过循环反馈机制不断优化生成过程,展示了合成数据生成的新范式。这一创新可能会改变未来AI模型训练的标准和方法。
多领域应用的潜力
Autodata框架在计算机科学、法律推理和科学推理等多个领域的实验中表现出色,显示了其广泛的应用潜力。通过针对不同任务的优化,Autodata能够生成高质量的训练数据,帮助模型在复杂任务中提升推理能力,未来可能会在更多领域得到应用。
延伸问答
Meta的Autodata框架是如何提升数据质量的?
Autodata框架通过模拟数据科学家的智能体,进行数据生成、分析和迭代优化,从而不断提升数据质量。
合成数据在人工智能中的作用是什么?
合成数据能够生成稀缺的边缘案例与长尾场景,降低人工标注的难度与延迟,并在某些情况下提供更具挑战性的训练样本。
Autodata框架在不同任务中的表现如何?
Autodata在计算机科学、法律推理和科学推理任务中均表现出优越性,显著提升了模型性能。
什么是Agentic Self-Instruct方法?
Agentic Self-Instruct是一种通过智能体生成合成数据的方法,旨在提高数据的质量和挑战性。
Meta的Autodata框架如何处理数据分析?
Autodata框架在数据生成后会进行分析,以总结生成数据的优缺点,并反馈到数据生成阶段进行改进。
未来AI发展中,Autodata框架的潜力是什么?
Autodata框架为未来AI发展提供了新的数据生成范式,具有广泛的应用潜力,能够推动任务与基准构建方式的变革。
