
0423 - 大模型 LLM 与本地数据
原文中文,约700字,阅读约需2分钟。
📝
内容提要
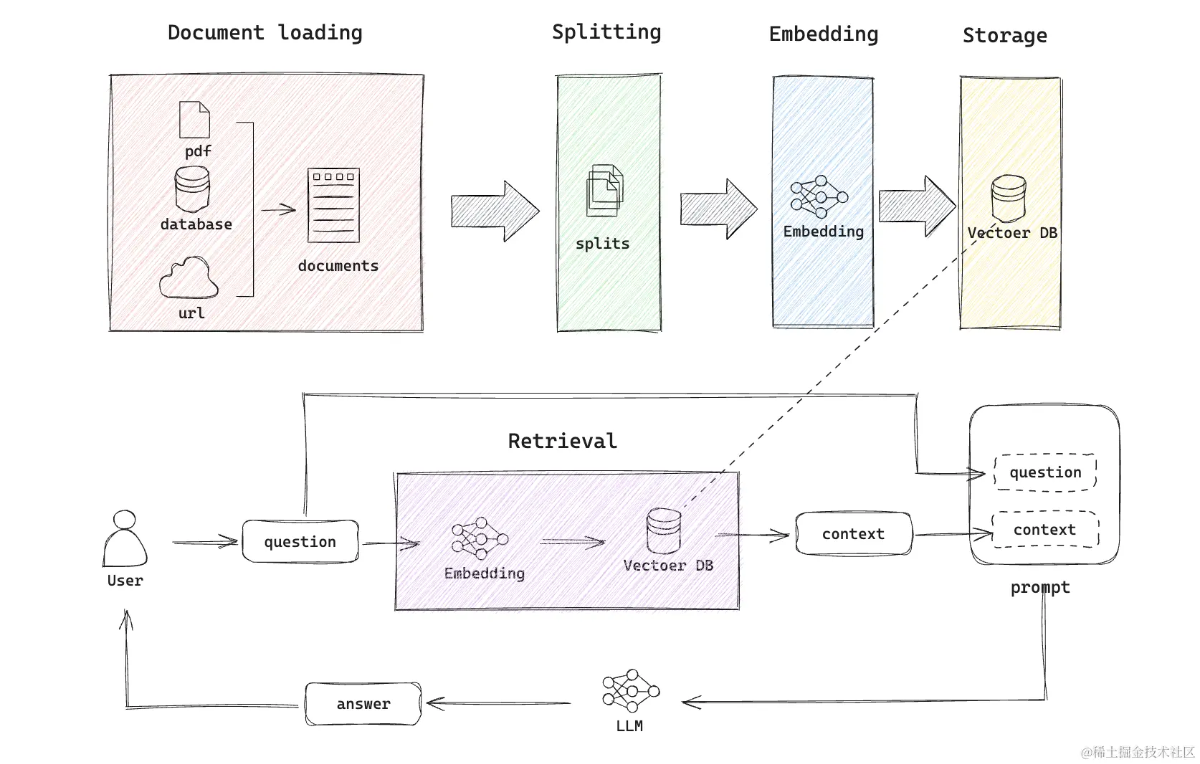
使用大模型查询本地数据的流程包括数据切割存储和计算向量。用户查询时,从数据库提取相关内容作为背景知识,与问题一起提交给大模型。高质量、规范化的数据是关键,但成本高昂。OpenAI的Assistants支持上传大量文件并使用GPT模型获取答案,适合个人和行业使用。
🎯
关键要点
-
使用大模型查询本地数据的流程包括将数据切割存储和计算向量。
-
用户查询时,从本地数据库提取相关内容作为背景知识,与问题一起提交给大模型。
-
高质量、规范化的数据是关键,但成本高昂。
-
使用ChatGPT等模型成本高,因为每次都需要传递大量上下文。
-
使用本地大模型可能导致回答质量差和计算速度慢。
-
可以用规范化的数据对大模型进行再训练,但这需要大量人力物力。
-
OpenAI的Assistants支持上传最多10万个文件和100GB的数据,适合个人和行业使用。
🏷️
