
数据库复制指南:关键概念与策略
内容提要
现代应用依赖数据,用户期望数据快速、实时且可访问。数据库复制通过在多台机器上保存相同数据,提高容错能力、扩展读取和减少延迟。尽管复制能确保系统在部分故障时继续运行,但也带来了如一致性和性能等复杂问题。本文探讨了复制延迟及当前分布式数据库的主要复制策略。
关键要点
-
现代应用依赖数据,用户期望数据快速、实时且可访问。
-
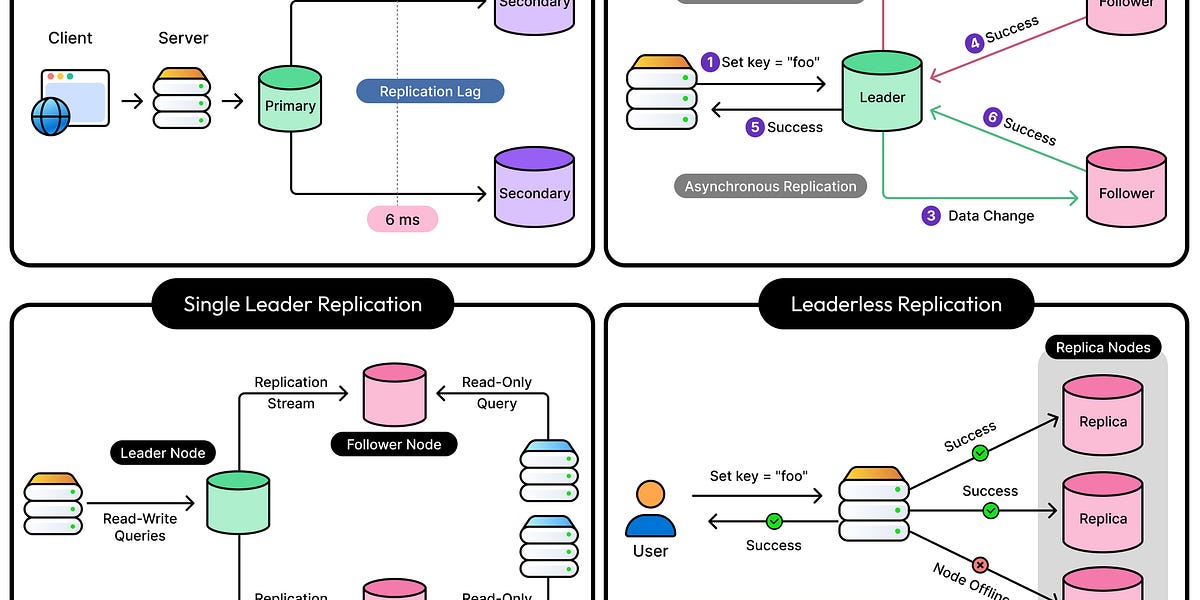
数据库复制是指在多台机器上保存相同数据,以提高容错能力、扩展读取和减少延迟。
-
复制确保系统在部分故障时继续运行,但也带来了如一致性和性能等复杂问题。
-
复制延迟是一个重要概念,本文将探讨当前分布式数据库的主要复制策略。
-
将讨论单领导、多领导和无领导复制模型,分析每种模型的工作原理、解决的问题及其局限性。
延伸解读
数据库复制的必要性
在现代应用中,数据的快速访问和实时更新至关重要。数据库复制通过在多台机器上保存相同数据,确保系统在部分故障时仍能正常运行。这种机制不仅提高了容错能力,还能扩展读取能力,减少延迟,满足用户对数据的高期望。
复制模型的复杂性
尽管数据库复制带来了许多好处,但也引入了复杂性,特别是在一致性和性能之间的权衡。不同的复制模型(如单领导、多领导和无领导)各有优缺点,设计时需考虑到潜在的延迟和数据一致性问题,以避免出现过时数据或数据冲突。
关注复制延迟
复制延迟是数据库复制中的一个重要概念,可能影响用户体验。即使主数据库正常运行,延迟的副本可能会提供过时的信息。因此,在选择复制策略时,需特别关注延迟问题,以确保用户获取到最新的数据。
延伸问答
数据库复制的主要目的是什么?
数据库复制的主要目的是提高容错能力、扩展读取和减少延迟。
复制延迟是什么?
复制延迟是指在数据库复制过程中,副本数据更新滞后于主数据的现象。
数据库复制带来了哪些复杂问题?
数据库复制带来了如一致性、可用性和性能等复杂问题。
有哪些主要的数据库复制模型?
主要的数据库复制模型包括单领导、多领导和无领导复制模型。
单领导复制模型的工作原理是什么?
单领导复制模型中,只有一个主节点负责写入操作,其他副本节点从主节点读取数据。
多领导复制模型有什么优势和局限性?
多领导复制模型允许多个节点同时进行写入,提升了可用性,但可能导致数据一致性问题。
