
利用PaddleOCR官网API高效完成医疗证照结构化处理
内容提要
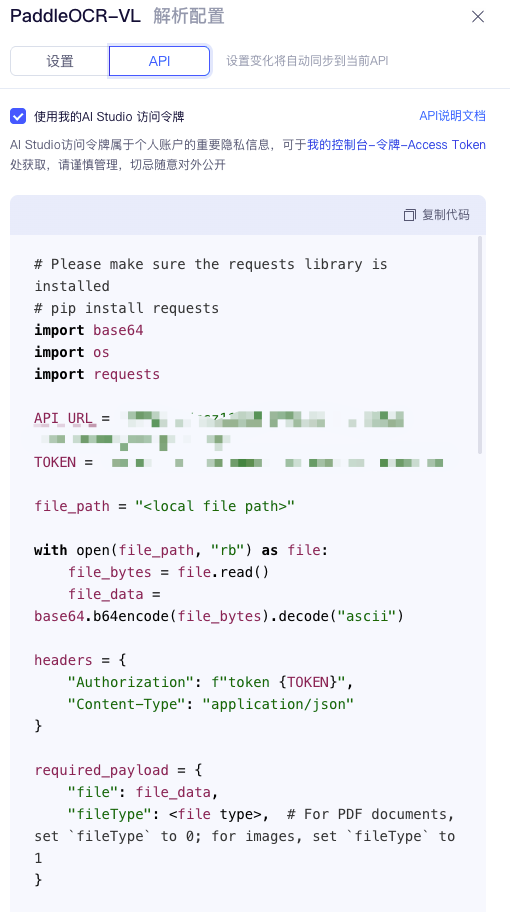
该文章介绍了一个Python脚本,用于批量解析PDF和图像文件。脚本读取文件,进行Base64编码,发送API请求,并将解析结果保存为Markdown和JSON格式,同时下载相关图片。
关键要点
-
该文章介绍了一个Python脚本,用于批量解析PDF和图像文件。
-
脚本读取文件,进行Base64编码,发送API请求。
-
解析结果保存为Markdown和JSON格式,同时下载相关图片。
-
定义了文件类型的扩展名,包括PDF和图像格式。
-
使用requests库发送POST请求,并处理响应结果。
-
保存解析结果时,分别生成Markdown和JSON文件。
-
处理Markdown中的图片和输出图像的下载。
-
提供了批量解析目录的功能,支持多个文件的处理。
-
脚本的主函数指定输入和输出目录,并执行解析操作。
延伸解读
脚本的实用性
该Python脚本能够高效处理医疗证照的PDF和图像文件,适合需要批量解析文档的用户。通过Base64编码和API请求,用户可以快速获取结构化数据,节省了手动处理的时间和精力。
文件类型支持
脚本支持的文件类型包括PDF和多种图像格式(如JPEG和PNG),这使得其适用范围广泛。用户在使用时需确保文件格式符合要求,以避免解析失败。
结果保存方式
解析结果以Markdown和JSON格式保存,便于后续的数据处理和分析。Markdown格式适合文档展示,而JSON格式则方便程序化处理,用户可以根据需求选择合适的格式。
API请求的注意事项
在发送API请求时,需确保正确配置Authorization和Content-Type头信息。错误的配置可能导致请求失败,用户应仔细检查API文档以确保请求的有效性。
延伸问答
这个Python脚本的主要功能是什么?
该Python脚本用于批量解析PDF和图像文件,并将解析结果保存为Markdown和JSON格式。
如何使用这个脚本处理文件?
脚本通过指定输入和输出目录,读取文件,进行Base64编码,发送API请求,并保存解析结果。
脚本支持哪些文件类型?
脚本支持PDF和多种图像格式,如JPG、JPEG和PNG。
解析结果是如何保存的?
解析结果分别保存为Markdown和JSON文件,同时下载相关图片。
如何处理Markdown中的图片?
脚本会提取Markdown中的图片链接并下载这些图片到指定的输出目录。
这个脚本如何处理多个文件?
脚本提供了批量解析目录的功能,可以同时处理多个文件。
