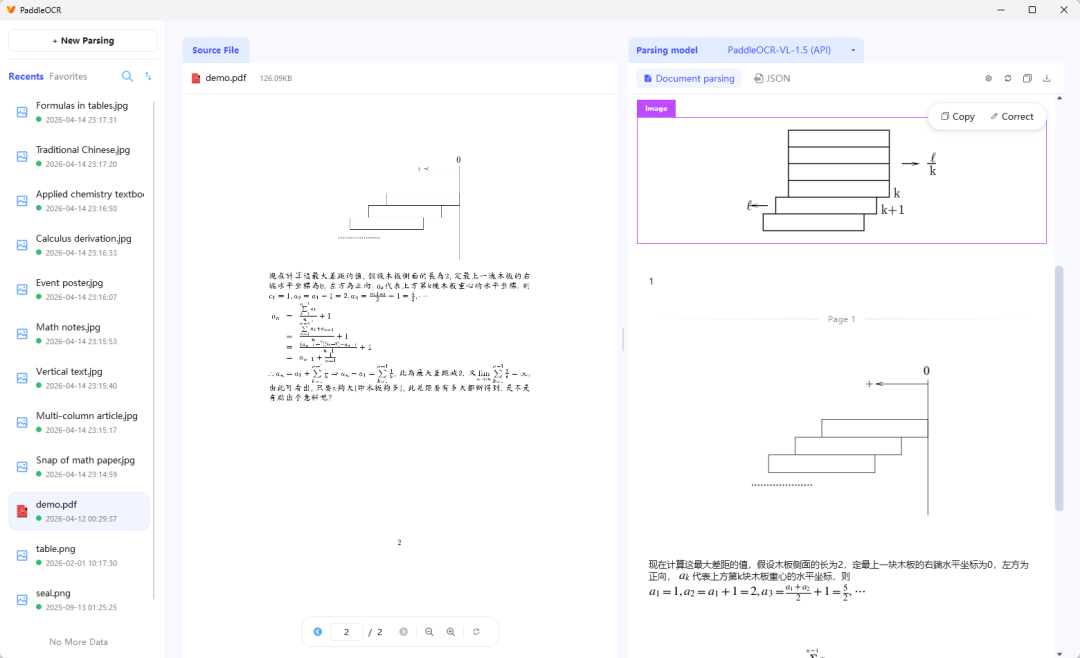
百度发布的PaddleOCR-VL-1.6在OmniDocBench v1.6评测中准确率超过96.3%,综合性能全球第一,支持100多种语言,适应复杂文档场景,满足文档数字化需求。该模型已上线官网并开源,供全球开发者使用。
PaddleOCR-VL-1.6正式发布,基于1.5版本进行了优化,文档解析性能显著提升,OmniDocBench v1.6指标突破96.3%。新版本支持异形框定位,增强了表格、古籍及生僻字的识别能力,模型结构保持一致,用户可快速适配。此外,PaddleOCR-VL系列与多家硬件及云平台合作,推动文档智能化转型。
PaddleOCR与CVHub合作推出X-AnyLabeling工具,支持PaddleOCR-VL-1.5模型,提升复杂文档的解析、复核和结构化导出能力。该工具简化了OCR数据准备流程,支持多任务解析,降低人工标注成本,助力开发者高效完成文档处理和数据沉淀。X-AnyLabeling被指定为PaddleOCR全球衍生模型挑战赛的官方标注平台。
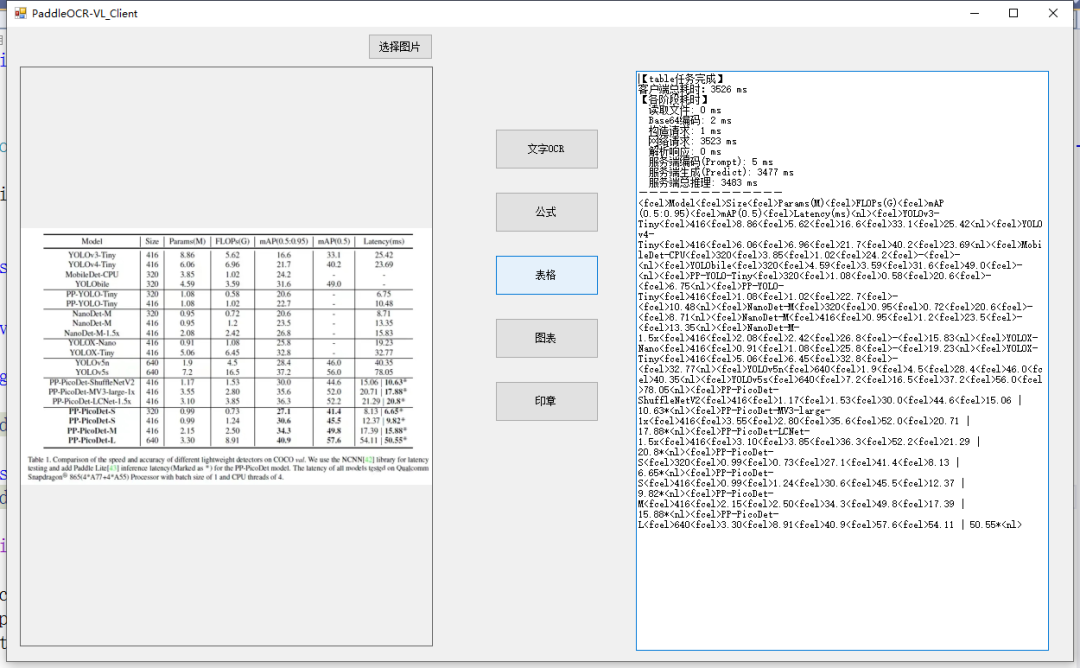
本文介绍了如何使用C# WinForm结合PaddleOCR-VL-1.5模型,构建一个本地离线的OCR客户端。该客户端支持多种识别任务,包括文字、表格和公式,架构简单,服务端与客户端解耦,便于升级和维护。通过RestSharp实现HTTP请求,确保识别过程的安全与高效。
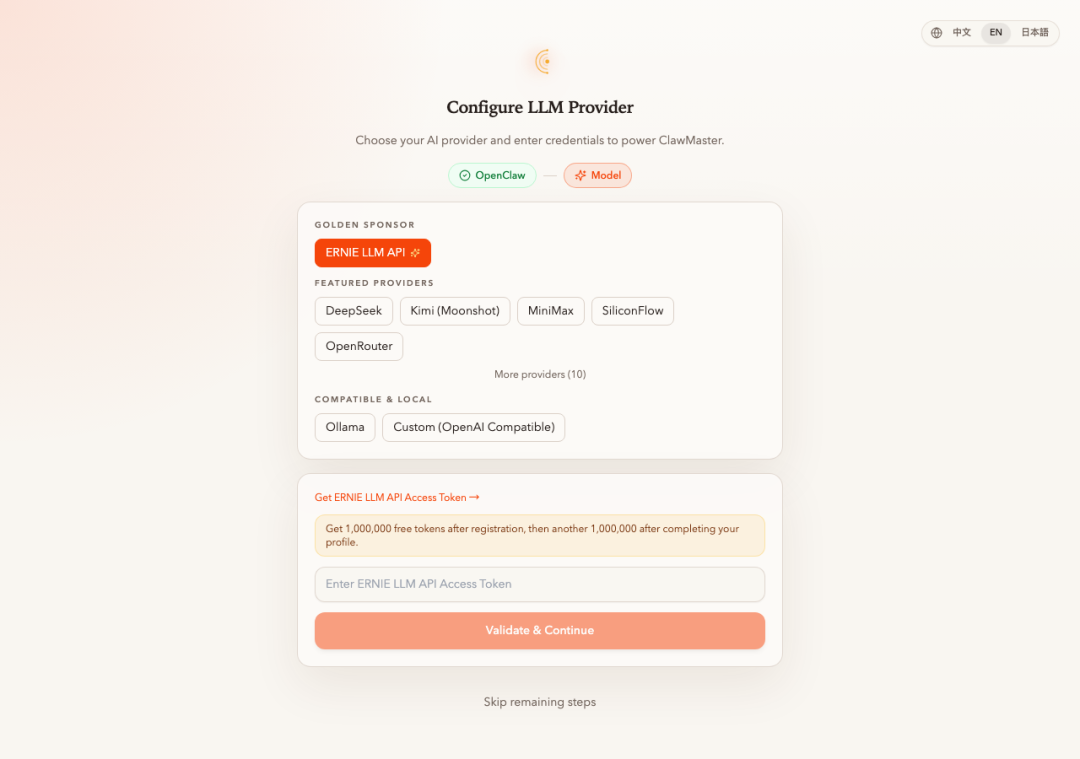
ClawMaster是一个可视化管理工具,整合了PaddleOCR、OpenClaw和PowerMem,旨在简化文档智能体的构建流程。它支持OCR解析、任务组织和记忆沉淀,实现文档处理的智能化,帮助开发者快速搭建应用,提高效率,并探索Agent的自动运维能力。
PaddleOCR 3.5正式发布,新增PaddleOCR.js,支持浏览器端OCR功能,简化开发者体验。可将文档解析结果导出为Word和Markdown格式,并支持多种文档类型。此版本整合了Transformers推理引擎,提升了OCR能力的灵活性和兼容性,旨在降低AI应用开发门槛,推动OCR技术发展。
中国煤科西安研究院引入AI技术,开发了智能铭牌识别系统,提升了设备信息采集的效率和准确性。该系统通过OCR和视觉语言模型,实现了数据的自动流转,减少了人工录入,提高了数据质量和管理效率,为煤炭行业的数字化转型提供了支持。
PaddleOCR在GitHub上的Star数超过Tesseract,成为全球第一的OCR开源项目。同时,PaddleOCR OCEAN生态联盟成立,旨在推动OCR技术的应用与生态繁荣,吸引全球开发者与企业合作。
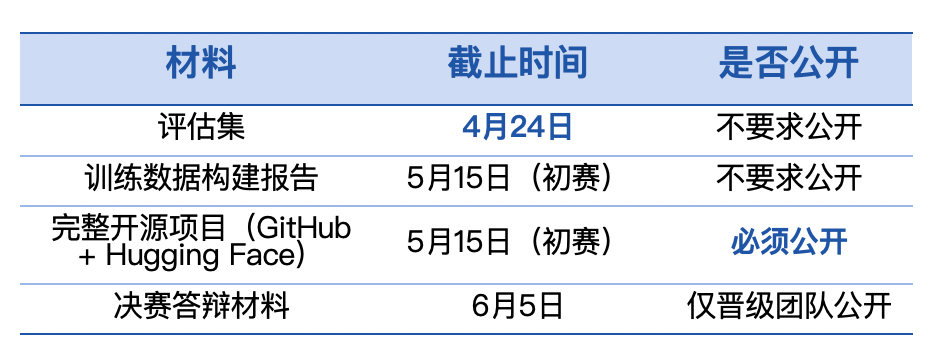
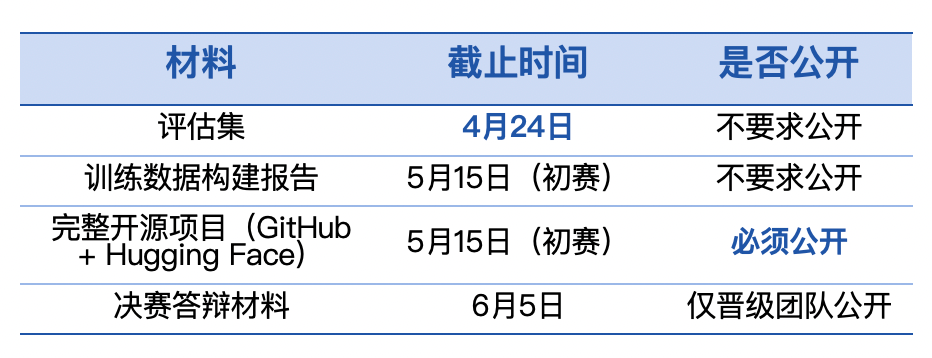
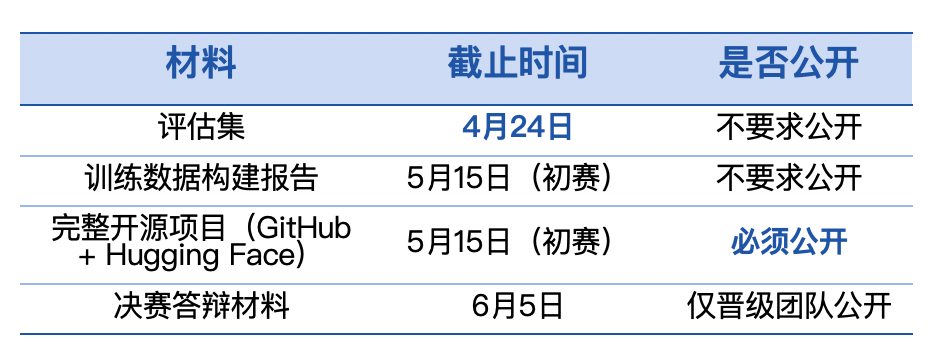
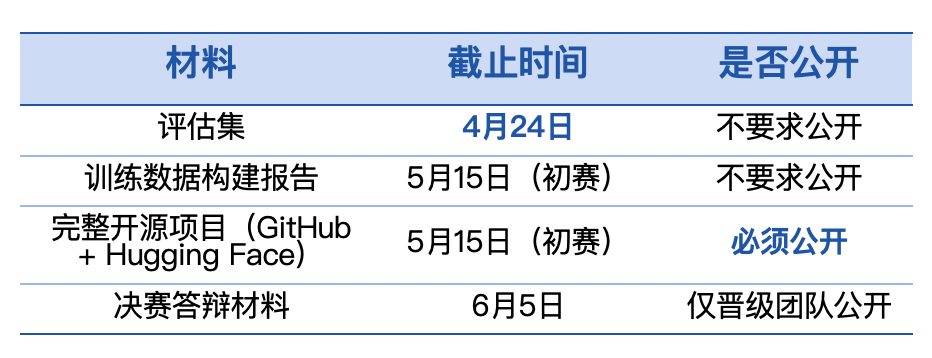
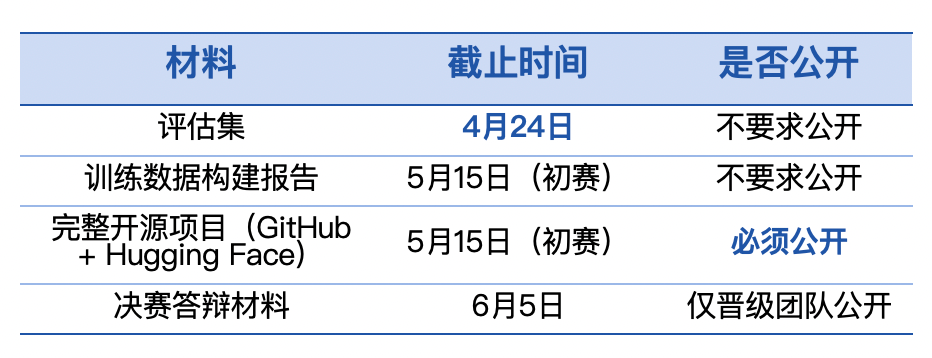
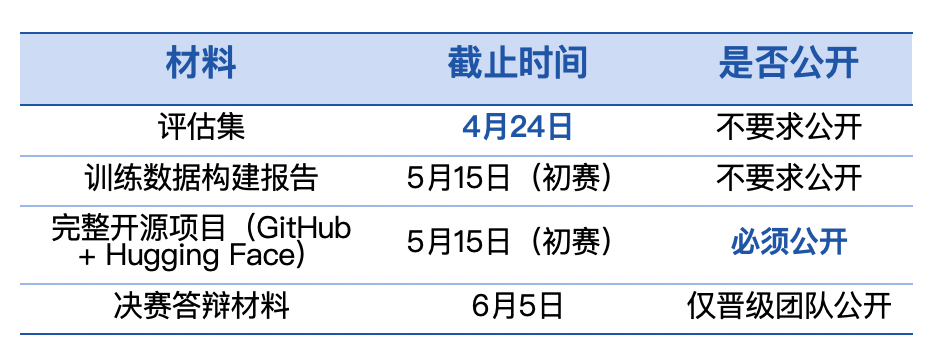
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元的奖金。比赛鼓励解决小语种识别和医疗处方等稀缺场景的OCR难题。优秀作品将获得展示机会和指导,参与者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元的奖金。比赛鼓励解决稀缺场景的OCR难题,如小语种识别和医疗处方。优秀作品将获得展示机会和指导,参与者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调训练,争夺总额7万元现金大奖。比赛鼓励解决稀缺场景的OCR难题,如小语种识别和医疗处方等。优秀作品将获得展示机会和指导,参与者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元现金大奖。比赛鼓励研究稀缺场景,如小语种OCR和医疗处方识别等。优秀作品将获得展示机会、论文指导及实习通道。报名和提交材料需通过指定渠道进行。
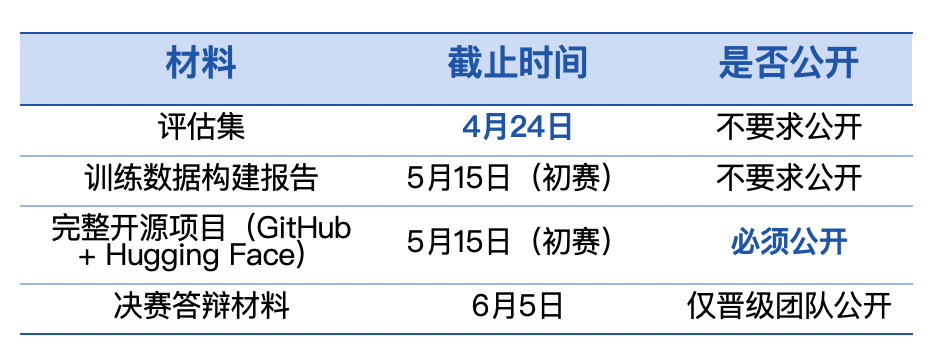
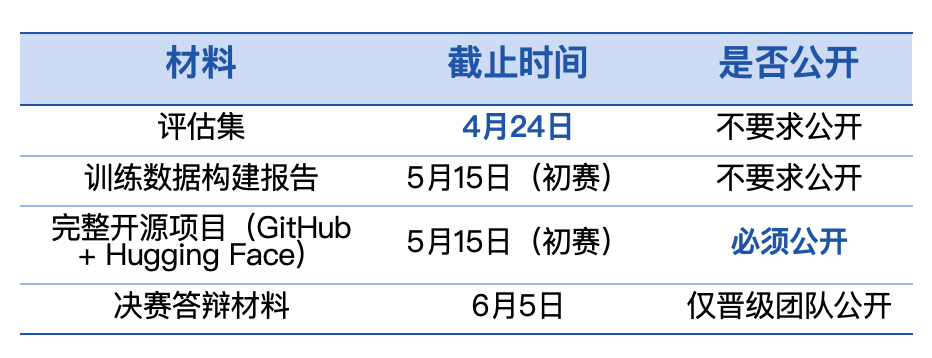
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元现金大奖。比赛鼓励解决小语种识别和医疗处方等稀缺场景的OCR难题。优秀作品将获得展示机会和指导,参赛者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元的奖金。比赛鼓励探索小语种OCR和医疗处方识别等稀缺场景,评分体系明确奖励行业刚需的选题。优秀作品将获得展示机会和深度指导,参赛者需自备算力。
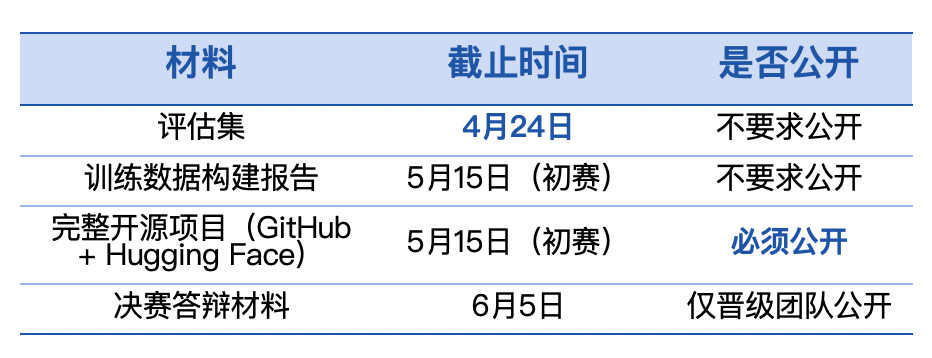
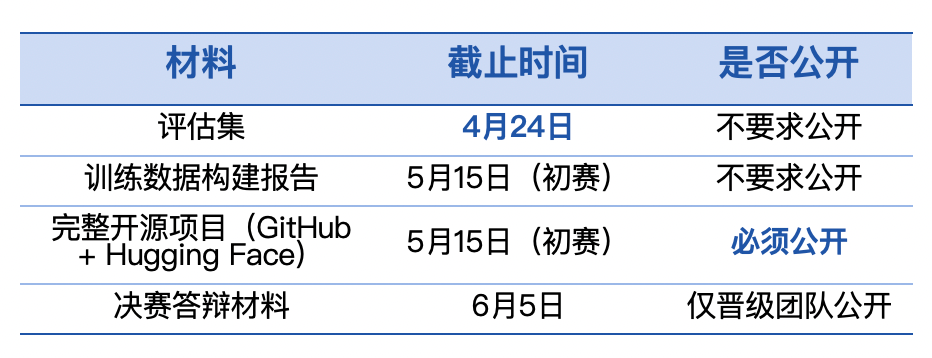
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元的奖金。比赛鼓励解决小语种识别和医疗处方等稀缺场景的OCR难题。优秀作品将获得展示机会和指导,参赛者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元的奖金。比赛鼓励解决稀缺场景的OCR难题,如小语种识别和医疗处方。优秀作品将获得展示机会和指导,参赛者需自备算力。
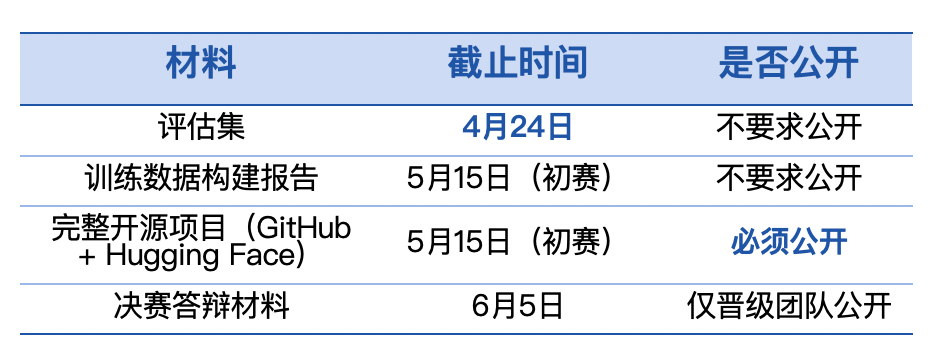
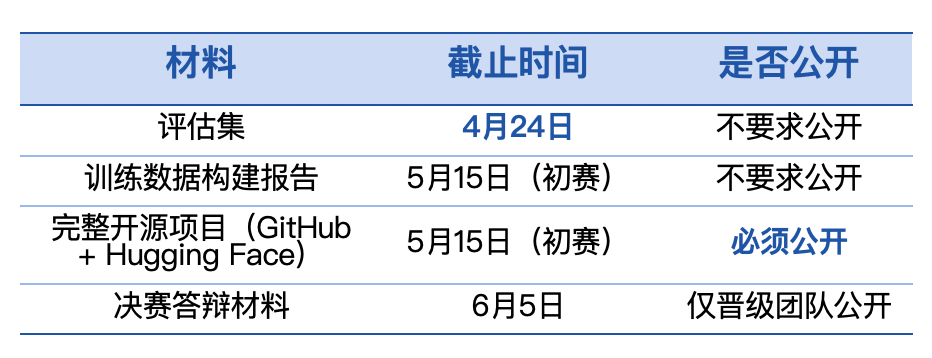
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调训练模型,争夺总额7万元的奖金。比赛鼓励解决稀缺场景的OCR难题,如小语种识别和医疗处方。优秀作品将获得展示机会和指导,参与者需自备算力。
第十届飞桨黑客马拉松推出「PaddleOCR全球衍生模型挑战赛」,面向全球开发者。参赛者可自定义赛题,微调模型,争夺总额7万元现金大奖。比赛鼓励解决稀缺场景的OCR难题,如小语种识别和医疗处方。优秀作品将获得展示机会和指导,参与者需自备算力。
完成下面两步后,将自动完成登录并继续当前操作。