
ChatGPT使用的Transfomer模型
原文中文,约17000字,阅读约需41分钟。
📝
内容提要
本文介绍了Transformer模型在LLAMA中的应用,包括网络结构、注意力机制和实现细节。同时提到使用ChatGPT辅助理解代码和问题,并计划在后续文章中分享更多关于ChatGPT技术原理的内容。
🎯
关键要点
-
本文介绍了Transformer模型在LLAMA中的应用,包括网络结构、注意力机制和实现细节。
-
作者是一名对AI技术感兴趣的软件开发工程师,早在深度学习兴起时就开始学习相关技术。
-
ChatGPT的发布使得重新学习相关技术变得必要,作者计划通过系列文章分享学习过程中的理解。
-
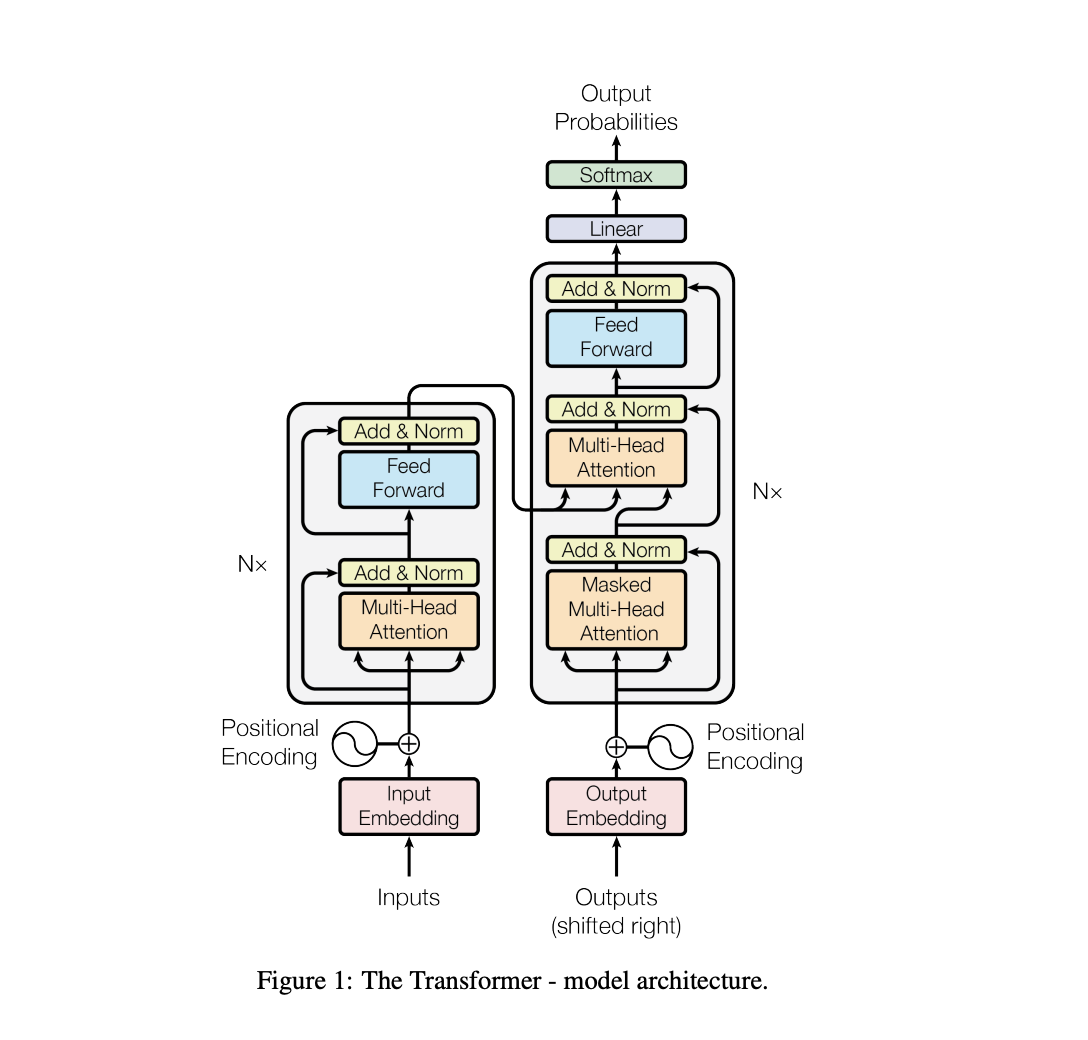
Transformer模型的结构由编码器和解码器组成,强调了注意力机制的重要性。
-
原始的Transformer模型复杂,但通过堆叠多个相同层可以实现强大的能力。
-
ChatGPT中的Transformer模型简化为只有一个Decoder模块,使用Masked Self-Attention。
-
LLAMA模型的代码实现简短,适合学习,结合代码分析Transformer的计算过程。
-
文本生成逻辑中,词嵌入使用SentencePiece库进行文本编码。
-
温度参数和top-p参数用于控制生成文本的多样性和选择范围。
-
Transformer模型的结构包括多个关键组件,如TransformerBlock、注意力机制和前馈神经网络。
-
注意力机制通过计算查询与键的相似度来为每个位置分配权重,提升模型的表达能力。
-
旋转嵌入技术增强了模型对序列中顺序关系的建模能力。
-
RMSNorm是一种归一化技术,用于增强网络的鲁棒性和稳定性。
-
掩码用于在计算注意力时遮蔽无效位置,确保模型的自回归性质。
-
作者借助ChatGPT辅助理解代码,提升了学习效率,并计划分享更多关于ChatGPT技术原理的内容。
🏷️
