
Lyft如何构建一个每秒处理数百万次预测的机器学习平台
内容提要
Lyft开发了LyftLearn Serving平台,采用微服务架构,简化机器学习模型服务的复杂性。各团队可独立管理微服务,支持多种机器学习库,提升部署效率和稳定性。平台的自动化测试确保模型持续有效,目前已有40多个团队使用,处理数亿次预测。
关键要点
-
Lyft开发了LyftLearn Serving平台,采用微服务架构,简化机器学习模型服务的复杂性。
-
各团队可独立管理微服务,支持多种机器学习库,提升部署效率和稳定性。
-
平台的自动化测试确保模型持续有效,目前已有40多个团队使用,处理数亿次预测。
-
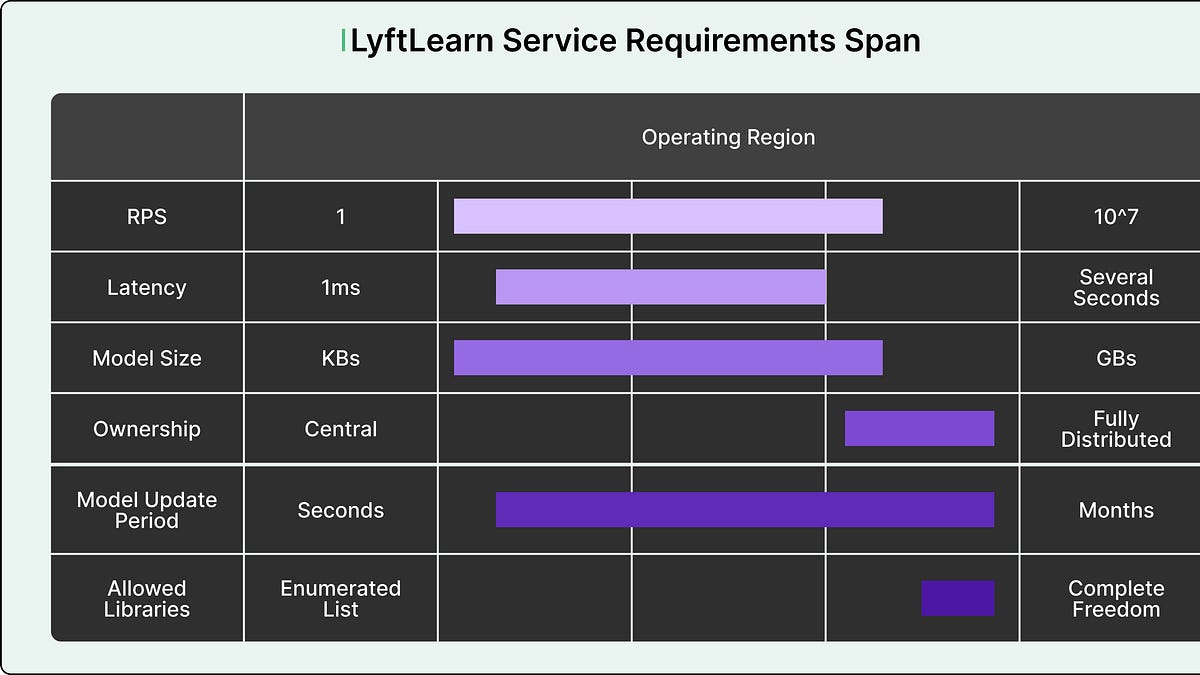
Lyft识别到机器学习模型服务的复杂性主要体现在数据平面和控制平面。
-
不同团队对系统特性的需求差异使得构建统一解决方案几乎不可能。
-
Lyft选择使用微服务架构,允许每个团队创建独立的微服务,解决了遗留系统中的所有权问题。
-
LyftLearn Serving的运行架构包括HTTP服务基础设施、核心库和第三方机器学习库。
-
配置生成器简化了微服务的部署过程,减少了对ML工程师的学习负担。
-
模型自测试功能确保模型在系统演变过程中持续正常工作。
-
LyftLearn Serving的请求处理流程高效且快速,通常在毫秒内完成。
-
Lyft提供了两种主要的工作方式,适应不同用户的需求。
-
良好的文档对于平台产品至关重要,能够促进自助入门并减少支持负担。
-
Lyft从构建LyftLearn Serving中总结了多个重要经验教训,包括定义术语、关注稳定性和文档的重要性。
延伸解读
微服务架构的优势
Lyft选择微服务架构来构建LyftLearn Serving平台,这一决策使得各团队能够独立管理自己的服务,避免了传统单体系统中的相互依赖问题。每个团队可以根据自身需求选择不同的机器学习库和版本,提升了灵活性和部署效率。
自动化测试的重要性
LyftLearn Serving平台内置的模型自测试功能确保了模型在系统演变过程中持续有效。通过自动化测试,团队能够及时发现潜在问题,减少了手动验证的负担,提高了模型的稳定性和可靠性。
文档与用户体验
Lyft团队强调了良好文档的重要性,清晰的文档能够促进用户自助入门,减少支持负担。通过提供多种文档类型,Lyft确保不同背景的用户都能顺利使用平台,提升了整体用户体验。
延伸问答
LyftLearn Serving平台的主要功能是什么?
LyftLearn Serving平台简化了机器学习模型服务的复杂性,支持多种机器学习库,并允许各团队独立管理微服务。
Lyft选择微服务架构的原因是什么?
Lyft选择微服务架构是为了允许每个团队创建独立的微服务,解决遗留系统中的所有权问题,并满足不同团队的需求。
LyftLearn Serving如何确保模型的持续有效性?
平台通过自动化测试和模型自测试功能,确保模型在系统演变过程中持续正常工作。
LyftLearn Serving的请求处理流程是怎样的?
请求通过HTTP POST发送到/infer端点,Flask服务器接收请求并调用相应的处理函数,最终返回预测结果。
LyftLearn Serving如何支持不同团队的需求?
平台允许每个团队使用配置生成器创建独立的微服务,支持不同的机器学习库和版本,满足各自的特定需求。
Lyft在构建LyftLearn Serving过程中总结了哪些经验教训?
Lyft总结了定义术语的重要性、模型稳定性、文档的重要性、不可避免的权衡以及与用户需求对齐的经验教训。
