
通过简单句子让嵌入模型理解文件和文件夹(杂乱文件夹重组AI)
内容提要
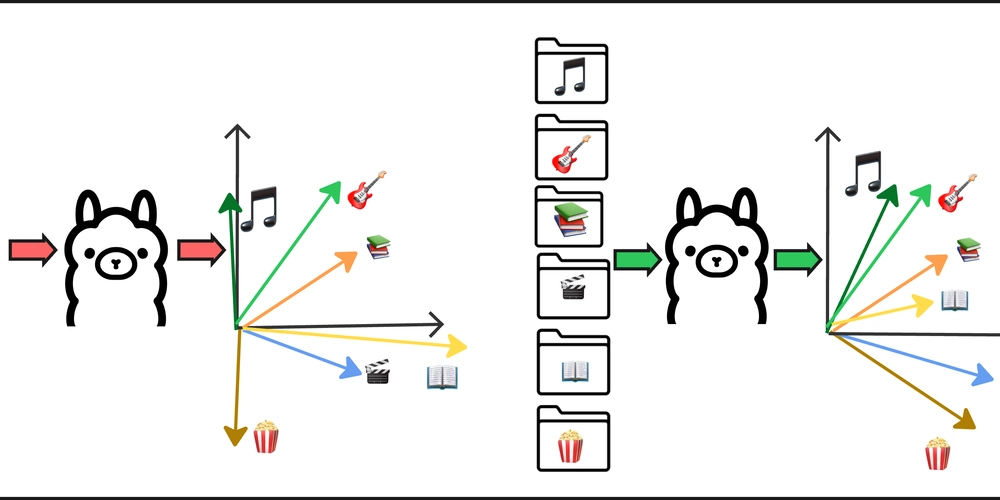
嵌入模型在文件分类和匹配中表现优异,添加自然语言上下文能显著提升准确性。通过结构化文件和文件夹名称,模型更好地理解语义,减少错误匹配。因此,为嵌入提供上下文是提升性能的关键。
关键要点
-
嵌入模型在文件分类和匹配中表现优异。
-
添加自然语言上下文能显著提升模型的准确性。
-
通过结构化文件和文件夹名称,模型更好地理解语义,减少错误匹配。
-
测试结果显示,添加上下文后,模型的匹配得分普遍提高。
-
上下文提供了结构,使嵌入模型更好地理解字符串的语义角色。
-
仅依靠词重叠并不能解释得分的提高,模型使用真正的上下文来判断兼容性。
-
没有上下文的原始字符串可能会导致误导,增加错误匹配的风险。
-
结论是嵌入模型在分类或匹配任务中需要上下文,提供自然语言结构显著提高性能。
-
在构建依赖嵌入的工具时,添加上下文是非常重要的。
延伸解读
上下文的重要性
嵌入模型在处理文件分类和匹配时,添加自然语言上下文显著提高了准确性。这表明,模型不仅依赖于词汇重叠,而是通过上下文理解字符串的语义角色,从而减少错误匹配的风险。
模型性能的提升
测试结果显示,添加上下文后,模型的匹配得分普遍提高。这意味着在构建依赖嵌入的工具时,提供结构化的上下文是提升性能的关键,尤其是在分类和推荐任务中。
潜在的误导风险
没有上下文的原始字符串可能导致误导,增加错误匹配的风险。例如,模糊的文件和文件夹名称可能会被错误地关联。通过简单的上下文包装,可以帮助模型更好地理解和区分不同的内容。
延伸问答
嵌入模型在文件分类中有什么优势?
嵌入模型在文件分类和匹配中表现优异,能够有效处理内容的自动分类。
添加自然语言上下文如何影响模型的准确性?
添加自然语言上下文显著提升了模型的准确性,测试结果显示匹配得分普遍提高。
为什么仅依靠词重叠不能提高模型得分?
仅依靠词重叠无法解释得分的提高,模型使用真正的上下文来判断兼容性。
如何通过结构化文件和文件夹名称来提高模型理解?
通过结构化文件和文件夹名称,模型能够更好地理解语义,减少错误匹配。
没有上下文的原始字符串会导致什么问题?
没有上下文的原始字符串可能会导致误导,增加错误匹配的风险。
在构建依赖嵌入的工具时,为什么添加上下文很重要?
添加上下文是提升嵌入模型性能的关键,能够显著提高分类和匹配的准确性。
