
Lyft重构机器学习平台,采用混合AWS SageMaker-Kubernetes方案
内容提要
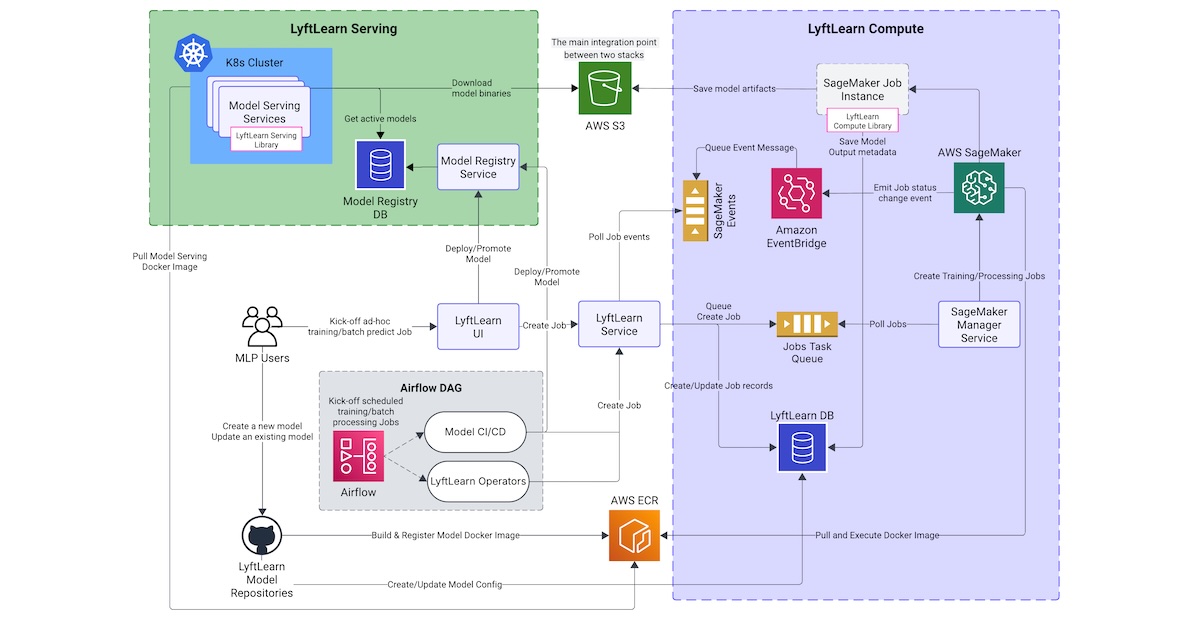
Lyft将其机器学习平台LyftLearn重构为混合系统,离线工作负载迁移至AWS SageMaker,在线模型服务保留在Kubernetes上。这一变革简化了操作复杂性,提高了工程效率,并支持数百万次日常预测,同时确保与现有ML代码兼容,减少基础设施事件,提升平台能力。
关键要点
-
Lyft将机器学习平台LyftLearn重构为混合系统,离线工作负载迁移至AWS SageMaker,在线模型服务保留在Kubernetes上。
-
这一变革简化了操作复杂性,提高了工程效率,并支持数百万次日常预测。
-
Lyft的工程师将LyftLearn Compute迁移至AWS SageMaker,消除了背景监视服务和集群自动扩展的挑战。
-
LyftLearn Serving仍然在Kubernetes上,保持了所需的性能和与内部工具的紧密集成。
-
Lyft选择SageMaker进行训练是因为管理自定义批处理计算基础设施消耗了大量工程能力。
-
LyftLearn支持数亿次日常预测,系统的操作复杂性随着规模的增长而增加。
-
SageMaker的托管基础设施直接解决了离线工作负载的痛点,采用事件驱动的状态管理。
-
Lyft构建了跨平台的Docker镜像,以在SageMaker中复制Kubernetes运行时环境。
-
最复杂的挑战是Spark在SageMaker Studio和EKS集群之间的双向通信需求。
-
迁移是逐个代码库部署的,两种基础设施并行运行,仅需最小的配置更改。
-
迁移后,Lyft报告基础设施事件减少,工程能力得以释放。
延伸解读
混合系统的优势
Lyft选择将离线工作负载迁移至AWS SageMaker,同时保留Kubernetes用于在线服务,这种混合架构有效降低了操作复杂性。通过将高复杂度的任务交给托管服务,Lyft能够将更多工程资源集中于机器学习平台的能力提升,优化了整体效率。
迁移过程中的挑战
在迁移过程中,Lyft面临了Spark在SageMaker Studio与EKS集群之间的双向通信需求的复杂挑战。通过与AWS合作,Lyft成功解决了网络配置问题,确保了系统性能不受影响。这一过程强调了在技术迁移中,定制化网络配置的重要性。
对工程团队的影响
迁移后,Lyft报告基础设施事件减少,工程团队的能力得以释放。这表明,合理的架构选择不仅能提升系统性能,还能减轻工程师的负担,使他们能够专注于更具创新性的工作,而不是日常的基础设施维护。
延伸问答
Lyft为什么选择将离线工作负载迁移到AWS SageMaker?
Lyft选择SageMaker是因为管理自定义批处理计算基础设施消耗了大量工程能力,SageMaker的托管基础设施直接解决了这些痛点。
Lyft的机器学习平台重构后有哪些主要变化?
Lyft将机器学习平台LyftLearn重构为混合系统,离线工作负载迁移至AWS SageMaker,在线模型服务保留在Kubernetes上。
Lyft在迁移过程中遇到了哪些挑战?
最复杂的挑战是Spark在SageMaker Studio和EKS集群之间的双向通信需求,默认的SageMaker网络阻止了Spark执行器与笔记本驱动程序之间的入站连接。
Lyft重构后的机器学习平台如何提高工程效率?
重构简化了操作复杂性,支持数百万次日常预测,并释放了工程能力,减少了基础设施事件。
Lyft如何确保迁移后的系统与现有ML代码兼容?
Lyft构建了跨平台的Docker镜像,以在SageMaker中复制Kubernetes运行时环境,确保兼容性。
Lyft的机器学习平台支持多少次日常预测?
LyftLearn支持数亿次日常预测,涵盖调度优化、定价和欺诈检测等领域。
