
AAAI 2026|MARS:基于多模态检索和选择增强的对话LLM语音识别
内容提要
西北工业大学与南洋理工大学合作提出MARS方法,通过多模态检索和选择历史上下文,提升对话语音识别(ASR)性能。该方法在MLC-SLM数据集上表现优异,展示了有效利用历史上下文的潜力。
关键要点
-
西北工业大学与南洋理工大学合作提出MARS方法,提升对话语音识别性能。
-
对话语音识别技术在智能助手和会议转录等应用中变得重要。
-
MARS方法通过多模态检索和选择历史上下文,增强对话ASR的性能。
-
研究表明,融入前序话语中的上下文能显著提升ASR性能。
-
MARS在MLC-SLM数据集上表现优异,混合错误率显著低于其他方法。
-
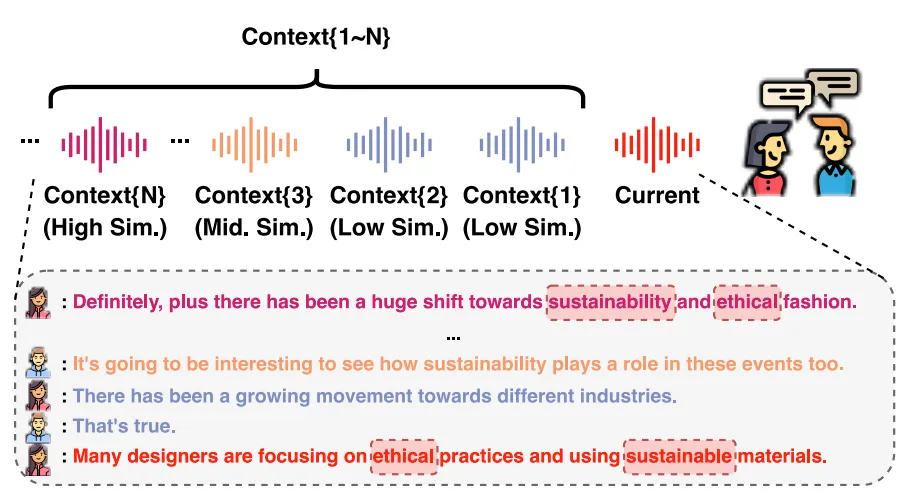
多模态检索结合语音和文本信息,减少ASR错误。
-
多模态选择模块从检索到的历史上下文中确定最佳上下文,提升ASR性能。
-
自适应上下文解码策略增强了对话LLM-ASR的泛化能力。
-
实验结果显示MARS方法在多语言对话语音识别中具有巨大潜力。
-
MARS方法通过有效选择历史上下文,降低计算成本并提升识别准确率。
延伸解读
对话语音识别的重要性
随着智能助手和会议转录等应用的普及,对话语音识别技术的需求日益增加。该技术不仅需要处理复杂的多说话人对话,还需理解上下文相关性,这对提升用户体验至关重要。MARS方法的提出正是为了应对这一挑战,提升对话ASR的性能。
多模态检索的优势
MARS方法通过结合语音和文本模态进行多模态检索,能够更全面地捕捉历史上下文信息。这种方法不仅减少了因发音变化和词语歧义引起的识别错误,还能有效降低计算成本,提升识别准确率。多模态检索的应用为对话ASR技术的发展提供了新的思路。
历史上下文选择的挑战
在对话ASR中,如何有效选择与当前话语相关的历史上下文是一个关键问题。MARS方法通过多模态选择模块,从检索到的历史上下文中挑选最佳上下文,避免了信息冗余带来的干扰。这一策略不仅提升了ASR性能,还降低了计算资源的消耗,具有重要的实用价值。
延伸问答
MARS方法的主要目标是什么?
MARS方法的主要目标是通过多模态检索和选择历史上下文,增强对话语音识别的性能。
MARS方法在MLC-SLM数据集上的表现如何?
MARS方法在MLC-SLM数据集上表现优异,混合错误率显著低于其他方法。
多模态检索在对话ASR中有什么优势?
多模态检索结合语音和文本信息,能够从发音和语义两个方面减少ASR错误。
MARS方法如何选择最佳历史上下文?
MARS方法通过多模态选择模块,从检索到的历史上下文中确定最佳上下文,以提升ASR性能。
MARS方法如何降低计算成本?
MARS方法通过有效选择历史上下文,降低了计算成本并提升了识别准确率。
自适应上下文解码策略的作用是什么?
自适应上下文解码策略增强了对话LLM-ASR的泛化能力,防止过度依赖历史上下文。
