


AMES:近似多模态企业搜索通过晚期交互检索
Apple Machine Learning Research
·
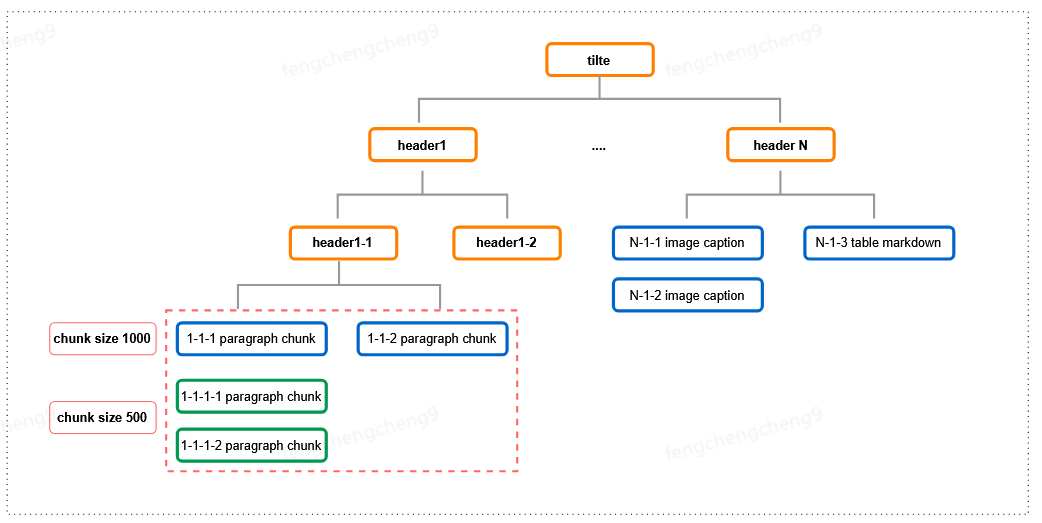
京东云JoyAgent持续开源!多模态RAG能力正式开源
京东科技开发者
·
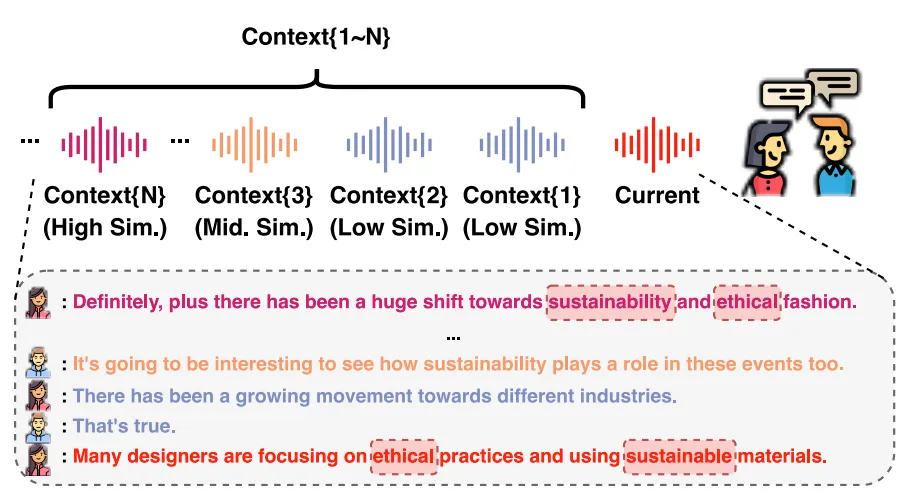

LlamaIndex通讯 2025年5月13日
Blog on LlamaIndex
·


使用 Sentrev 寻找合适的嵌入模型
Qdrant - Vector Database
·
