

多模态大语言模型基础:大语言模型如何处理文本、图像、音频和视频
💡
原文英文,约1800词,阅读约需7分钟。
📝
内容提要
静态训练数据无法适应快速变化的信息,导致模型只能进行猜测。本文介绍了多模态大语言模型(LLM)的原理,通过将文本、图像和音频转化为统一的数学表示,模型实现了跨模态推理,能够实时理解和响应。
🎯
关键要点
- 静态训练数据无法适应快速变化的信息,导致模型只能进行猜测。
- 多模态大语言模型(LLM)通过将文本、图像和音频转化为统一的数学表示,实现跨模态推理。
- 人类的认知是多模态的,AI系统需要将分离的感官通道融合。
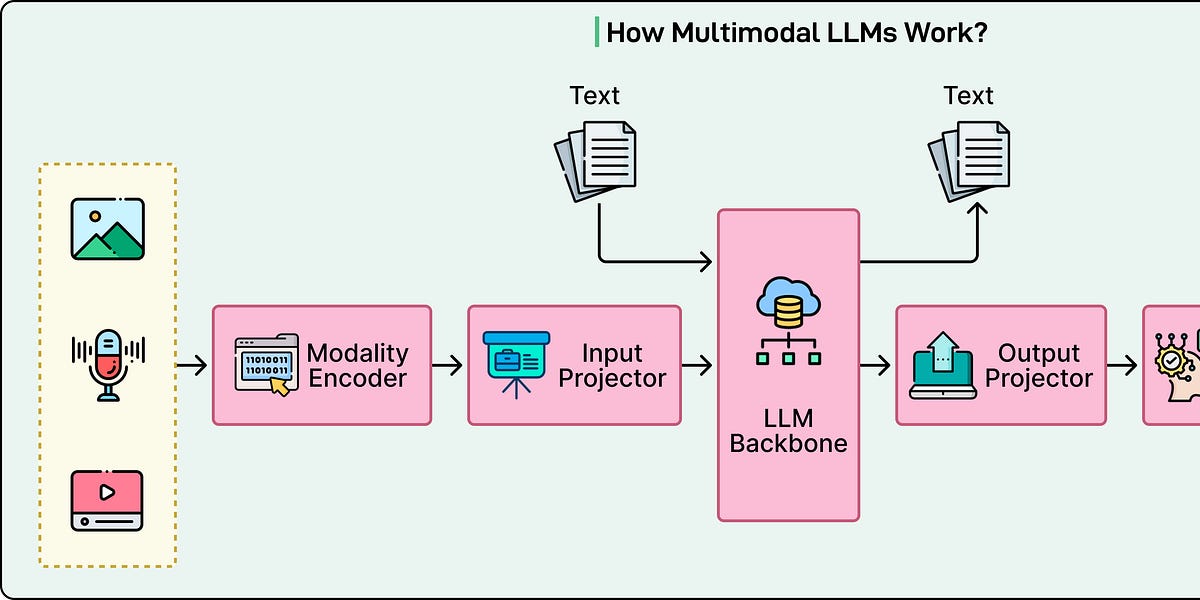
- 多模态LLM的核心突破是将不同类型的输入转换为相同的数学表示,称为嵌入向量。
- 现代多模态LLM由三个基本组件组成:特定模态编码器、投影层和语言模型主干。
- 视觉变换器将图像处理为句子,音频编码器将声音转换为声谱图。
- 投影层将不同模态的表示对齐到共享空间,使模型能够理解视觉和听觉概念。
- 训练过程分为两个阶段:特征对齐和视觉指令调优。
- CLIP通过对比学习改变了视觉编码器的训练方式,提升了图像与文本的匹配能力。
- 音频通过转换为声谱图,使其可以像图像一样被处理。
- 未来的趋势是任何对任何模型,能够理解和生成所有模态的输出。
➡️
