
摩尔线程S5000 + 智源FlagOS:基于原生FP8引擎,Day-0适配DeepSeek-V4
内容提要
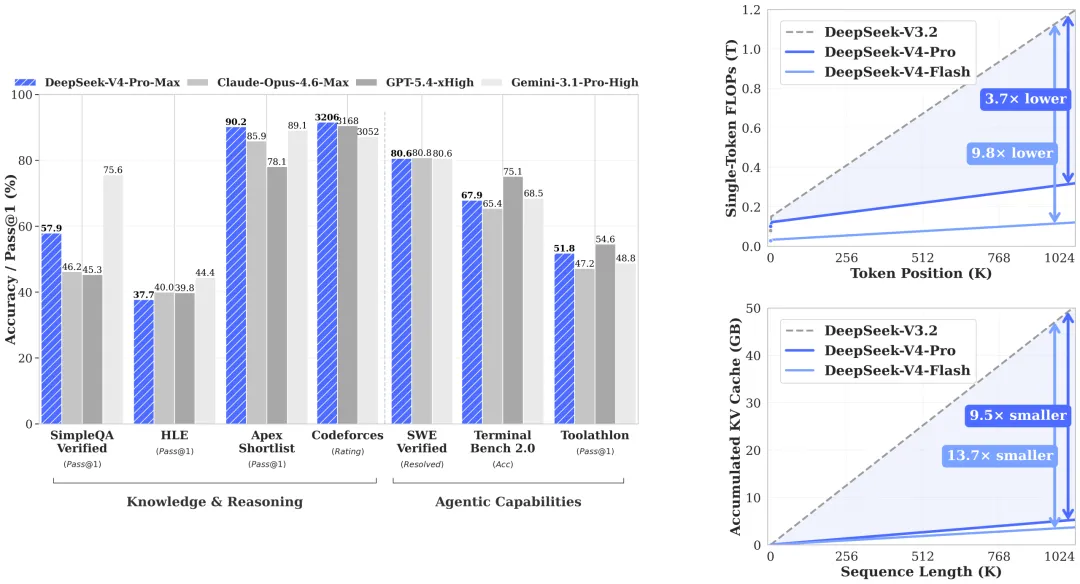
摩尔线程与智源众智FlagOS社区合作,在MTT S5000 GPU上快速适配DeepSeek-V4-Flash模型。该模型采用混合专家架构,参数量达到284B,支持百万token上下文。MTT S5000原生支持FP8精度,提升计算效率。双方通过编译优化和自动调优,提升了FP8和Sparse Attention算子的性能,降低延迟并提高吞吐量。未来将继续推进DeepSeek-V4-Pro的适配工作。
关键要点
-
摩尔线程与智源众智FlagOS社区合作,在MTT S5000 GPU上实现DeepSeek-V4-Flash模型的快速适配。
-
DeepSeek-V4-Flash模型采用混合专家架构,参数量达到284B,支持百万token上下文。
-
MTT S5000原生支持FP8精度,提升计算效率,显存带宽压力降低50%。
-
双方通过编译优化和自动调优,提升了FP8和Sparse Attention算子的性能,降低延迟并提高吞吐量。
-
未来将继续推进DeepSeek-V4-Pro的适配工作,进一步提升国产大模型生态的算力基础。
延伸解读
FP8精度的优势
摩尔线程的MTT S5000原生支持FP8精度,这一特性使得其在处理DeepSeek-V4-Flash模型时,显存带宽压力降低50%,计算效率显著提升。相比于传统的BF16/FP16,FP8能够更有效地利用显存资源,适合大规模模型的推理需求。
混合专家架构的潜力
DeepSeek-V4-Flash采用混合专家架构,参数量高达284B,支持百万token上下文。这种架构能够在不同任务中动态选择专家,提高模型的灵活性和效率,尤其在处理复杂任务时,展现出更强的推理能力。
优化策略的实施
摩尔线程与FlagOS团队通过编译优化和自动调优,显著提升了FP8和Sparse Attention算子的性能。这种系统级的优化策略不仅降低了延迟,还提高了吞吐量,为大模型的实际应用提供了更为可靠的技术支持。
延伸问答
摩尔线程与智源FlagOS的合作主要实现了什么?
摩尔线程与智源FlagOS合作在MTT S5000 GPU上快速适配了DeepSeek-V4-Flash模型。
DeepSeek-V4-Flash模型的参数量和上下文支持是多少?
DeepSeek-V4-Flash模型的参数量达到284B,支持百万token上下文。
MTT S5000 GPU的FP8精度有什么优势?
MTT S5000原生支持FP8精度,能够将数据位宽减半,显存带宽压力降低50%,计算吞吐量翻倍。
如何提升DeepSeek-V4模型的FP8和Sparse Attention算子性能?
通过编译优化和自动调优,提升FP8和Sparse Attention算子的性能,降低延迟并提高吞吐量。
DeepSeek-V4-Pro模型的适配工作进展如何?
摩尔线程与FlagOS社区正在推进DeepSeek-V4-Pro模型在MTT S5000上的迁移适配工作。
FlagOS-Tune的功能是什么?
FlagOS-Tune能够自动搜索最优的Triton内核配置,提升算子性能。
