
MOS-Bench:用于训练和评估主观语音质量评估 (SSQA) 模型的综合数据集
内容提要
主观语音质量评估(SSQA)面临模型推广的挑战,现有模型在不同领域表现不佳。为此,研究者提出了MOS-Bench基准和SHEET工具包,以增强模型的泛化能力和评估一致性。这些工具结合多数据集和新评估指标,推动SSQA研究进展,提高自动语音质量评估的有效性。
关键要点
-
主观语音质量评估(SSQA)面临模型推广的挑战,现有模型在不同领域表现不佳。
-
SSQA模型在跨领域表现不佳,主要由于不同任务之间的数据特征和评分系统差异。
-
当前SSQA方法包括基于参考和基于模型的方法,后者在捕捉人类感知方面具有潜力,但存在泛化约束和计算复杂性问题。
-
研究者提出MOS-Bench基准和SHEET工具包,以增强模型的泛化能力和评估一致性。
-
MOS-Bench包含七个训练数据集和十二个测试数据集,涵盖不同语音类型、语言和采样频率。
-
SHEET提供标准化的工作流程,支持SSQA模型的训练、验证和测试。
-
MOS-Bench与SHEET结合,允许系统地评估SSQA模型,特别关注模型的泛化能力。
-
MOS-Bench引入新的性能指标,以整体评估SSQA模型在不同数据集上的表现。
-
MOS-Bench数据集包括多种语言和领域的样本,增强了模型的训练范围。
-
使用MOS-Bench和SHEET显著提高了SSQA在合成和非合成测试集上的泛化能力。
-
MOS-Bench建立了可靠的基准,使SSQA模型能够在不同领域应用准确的性能。
-
该方法通过减少特定于数据集的偏差,推动SSQA研究的前沿,促进模型在各个应用程序之间的有效泛化。
延伸解读
SSQA模型的推广挑战
主观语音质量评估(SSQA)模型在不同领域的推广面临诸多挑战,尤其是由于数据特征和评分系统的差异,导致模型在新领域的表现不佳。这一问题限制了模型在实际应用中的有效性,尤其是在TTS和VC系统中。
MOS-Bench的创新意义
MOS-Bench通过整合多种数据集,提供了一个全面的评估框架,显著提高了SSQA模型的泛化能力。其引入的新性能指标和标准化工作流程,使得模型在不同条件下的评估更加一致和可靠,推动了SSQA研究的进展。
SHEET工具包的作用
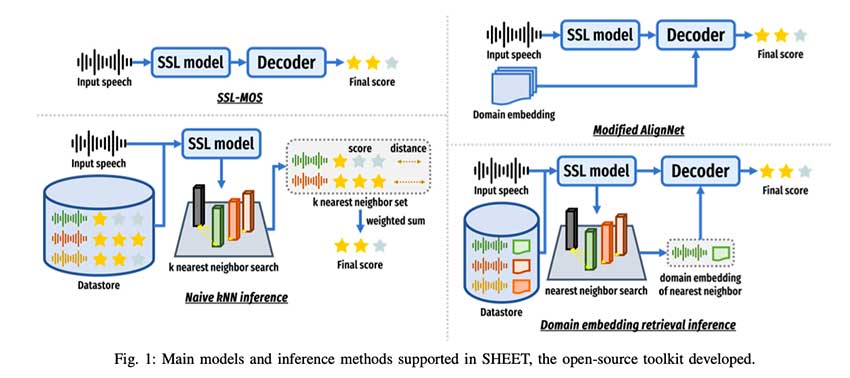
SHEET工具包为SSQA模型的训练、验证和测试提供了标准化的流程,增强了模型的鲁棒性。通过优化超参数和引入基于检索的评分方法,SHEET进一步提升了模型在多样化数据集上的表现,确保了更高的质量预测准确性。
延伸问答
MOS-Bench的主要功能是什么?
MOS-Bench是一个基准集合,包含七个训练数据集和十二个测试数据集,旨在增强主观语音质量评估模型的泛化能力和评估一致性。
SHEET工具包在SSQA模型中起什么作用?
SHEET工具包提供标准化的工作流程,支持SSQA模型的训练、验证和测试,提升模型的性能和一致性。
SSQA模型在不同领域表现不佳的原因是什么?
SSQA模型在不同领域表现不佳主要是由于不同任务之间的数据特征和评分系统差异,导致模型的泛化能力受限。
MOS-Bench如何提高SSQA模型的泛化能力?
MOS-Bench通过结合多数据集和引入新的评估指标,扩大模型在不同条件下的暴露范围,从而提高其泛化能力。
当前SSQA方法有哪些?
当前SSQA方法包括基于参考的方法和基于模型的方法,后者通过学习人工注释的数据集来捕捉人类感知。
MOS-Bench引入了哪些新的性能指标?
MOS-Bench引入了最佳得分差异/比率的新性能指标,以整体评估SSQA模型在不同数据集上的表现。
