
💡
原文中文,约3200字,阅读约需8分钟。
📝
内容提要
大模型的发展凸显了推理数据的重要性,优质推理数据集支持复杂推理任务。HyperAI整理了多领域推理数据集,降低了使用门槛,促进科研与模型训练。
🎯
关键要点
- 大模型的发展使推理数据的重要性重新定义。
- 高质量推理数据集支持复杂推理任务,如数学问题和跨领域知识问答。
- 推理数据集存在碎片化特征,使用门槛高,开发者和研究者耗费大量时间寻找数据。
- HyperAI 整理了多领域的优质推理数据集,降低了使用门槛。
- Open-RL 数据集包含多领域的独立 STEM 推理问题,适合强化学习微调。
- CHIMERA 数据集提供合成推理问题,涵盖多个学科,所有示例由大型语言模型生成。
- Nemotron-Math-v2 数据集用于训练 LLM 执行结构化数学推理,包含高质量数学问题。
- OmniSpatial 数据集填补视觉-语言模型空间理解评测的空白,适用于多模态大模型的训练与评测。
- FrontierScience 数据集评估大模型在科学推理与科研任务的能力,采用双层任务结构。
- HotpotQA 数据集需要在多个支持文档中查找和推理才能回答问题,具有多样性。
- VCR 数据集用于视觉常识推理,机器需回答问题并提供理由证明答案合理性。
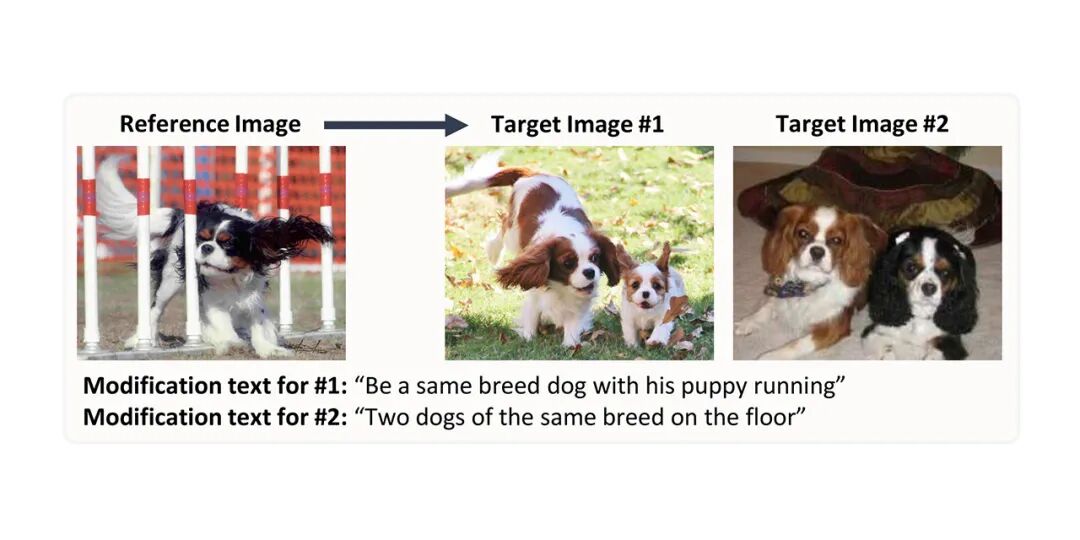
- CIRR 数据集促进视觉语言学概念的微妙推理研究,强调开放域视觉相似图像的区分。
❓
延伸问答
推理数据集对大模型的发展有什么影响?
推理数据集的重要性被重新定义,支持复杂推理任务,决定模型的上限。
HyperAI整理了哪些类型的推理数据集?
HyperAI整理了多领域的优质推理数据集,包括数学、科学推理、合成推理等。
Open-RL数据集的主要特点是什么?
Open-RL数据集包含多领域的独立STEM推理问题,适合强化学习微调,需多步推理。
OmniSpatial数据集的应用场景有哪些?
OmniSpatial数据集适用于训练与评测多模态大模型的空间推理能力,特别是在智能导航和复杂场景理解中。
HotpotQA数据集的特点是什么?
HotpotQA数据集需要在多个支持文档中查找和推理才能回答问题,具有多样性和复杂性。
VCR数据集的主要任务是什么?
VCR数据集要求机器回答关于图像的问题,并提供理由证明答案的合理性。
➡️
