
ChatGPT一周年:开源大模型迎头赶上?
原文中文,约2500字,阅读约需6分钟。
📝
内容提要
这篇综述文章总结了开源大型语言模型(LLM)在过去一年中的发展情况,包括兴起、进展、竞争和差异。文章提到了知识获取、情感分析、代码生成等具体研究成果和进展。最后,文章探讨了开源LLM的未来发展方向和伦理安全挑战。
🎯
关键要点
-
开源大型语言模型(LLM)在过去一年中取得显著进展,尤其是在自然语言处理任务上。
-
开源LLM与闭源LLM之间存在竞争,性能和应用方面存在差异。
-
具体研究成果包括知识获取、情感分析和代码生成等。
-
开源LLM的未来发展方向包括伦理和安全挑战的应对措施。
-
ChatGPT的发布引发了AI社区的广泛关注,用户数量迅速增长。
-
闭源模型的特性导致潜在风险难以评估,且存在性能波动和服务中断问题。
-
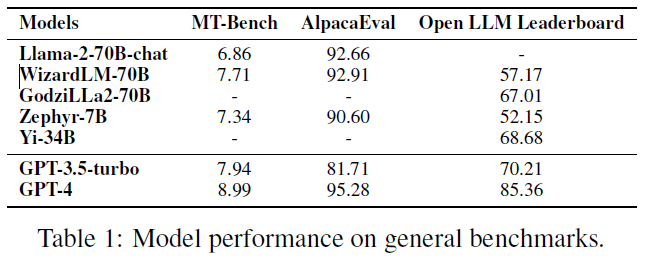
开源大模型如Llama-2和Falcon在性能上逐渐缩小与闭源模型的差距。
-
评估开源大模型的能力变得愈发重要,尤其是在Agent能力、逻辑推理和长上下文处理等方面。
-
大模型研究的趋势包括扩大模型参数和探索更好的预训练策略。
-
Meta发布的Llama系列模型推动了开源大模型的研究和应用。
-
研究者通过微调和生成指令数据来提升开源大模型的性能。
-
研发更强大和高效的开源大模型是未来的一个重要方向。
🏷️
