
MAF快速入门(7)工作流的状态共享
内容提要
本文介绍了MAF工作流中如何通过WorkflowContext实现多个步骤间的数据共享。以文档统计案例为例,展示了读取文件内容并统计单词和段落数的过程,最后聚合输出结果。
关键要点
-
MAF工作流中通过WorkflowContext实现多个步骤间的数据共享。
-
状态共享的应用场景包括用户输入和模型输出缓存等。
-
WorkflowContext提供状态读取和设置的接口,如QueueStateUpdateAsync和ReadStateAsync。
-
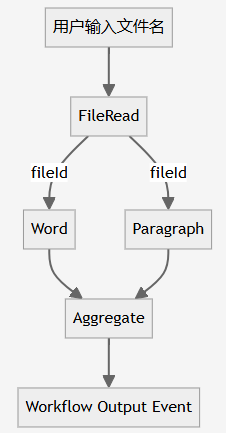
文档统计案例展示了扇入扇出工作流的实现过程。
-
用户输入文件名后,FileReadExecutor读取文件内容并共享给后续Executor。
-
文字统计和段落统计Executor分别统计文件的单词数和段落数。
-
聚合输出Executor汇总统计结果并通过LLM输出友好的信息。
-
工作流的构建包括获取ChatClient、实例化Executor和创建Fan-out/Fan-in工作流。
-
测试工作流的执行结果展示了统计和聚合的最终输出。
-
文章总结了工作流状态共享的应用场景和相关API,并提供了文档统计的案例。
延伸解读
状态共享的重要性
在MAF工作流中,状态共享通过WorkflowContext实现,允许多个步骤之间高效传递数据。这种机制在处理用户输入和模型输出时尤为重要,能够显著提高工作流的灵活性和响应速度。
扇入扇出的应用场景
本文中的文档统计案例展示了扇入扇出工作流的典型应用。通过将文件内容读取后分发给多个统计Executor,能够并行处理,提高效率。这种设计适合需要同时处理多个数据流的复杂业务场景。
API接口的实用性
WorkflowContext提供的QueueStateUpdateAsync和ReadStateAsync等API接口,简化了状态管理的复杂性。开发者可以通过这些接口轻松实现数据的存取,降低了开发门槛,提升了工作流的可维护性。
延伸问答
MAF工作流中的状态共享是如何实现的?
MAF工作流通过WorkflowContext实现多个步骤间的数据共享,允许在工作流中共享上下文数据。
WorkflowContext提供了哪些API接口?
WorkflowContext提供了状态读取和设置的接口,如QueueStateUpdateAsync和ReadStateAsync。
文档统计的工作流案例是如何构建的?
文档统计工作流通过用户输入文件名,FileReadExecutor读取文件内容并共享,随后进行单词和段落统计,最后聚合输出结果。
在MAF工作流中,如何处理用户输入和模型输出的缓存?
MAF工作流通过WorkflowContext实现用户输入和模型输出的缓存,确保多个Executor可以共享这些数据。
如何测试MAF工作流的执行结果?
可以通过创建工作流并使用InProcessExecution.StreamAsync方法来测试工作流的执行结果,观察各个节点的输出。
MAF工作流的聚合输出Executor是如何工作的?
聚合输出Executor汇总多个Executor的统计结果,并通过LLM生成用户友好的输出信息。
