
Timescale Vector与LlamaIndex:让PostgreSQL成为更好的AI应用向量数据库
内容提要
Timescale Vector集成了LlamaIndex,利用PostgreSQL作为向量数据库,提供快速的相似性搜索和高效的时间过滤。它支持多种索引算法,简化AI应用基础设施,允许开发者在一个数据库中管理向量、关系和时间序列数据。通过时间分区,Timescale Vector优化了基于时间的搜索,提升了查询效率,适用于需要时间上下文的检索增强生成(RAG)应用。
关键要点
-
Timescale Vector集成了LlamaIndex,使用PostgreSQL作为向量数据库,提供快速的相似性搜索和高效的时间过滤。
-
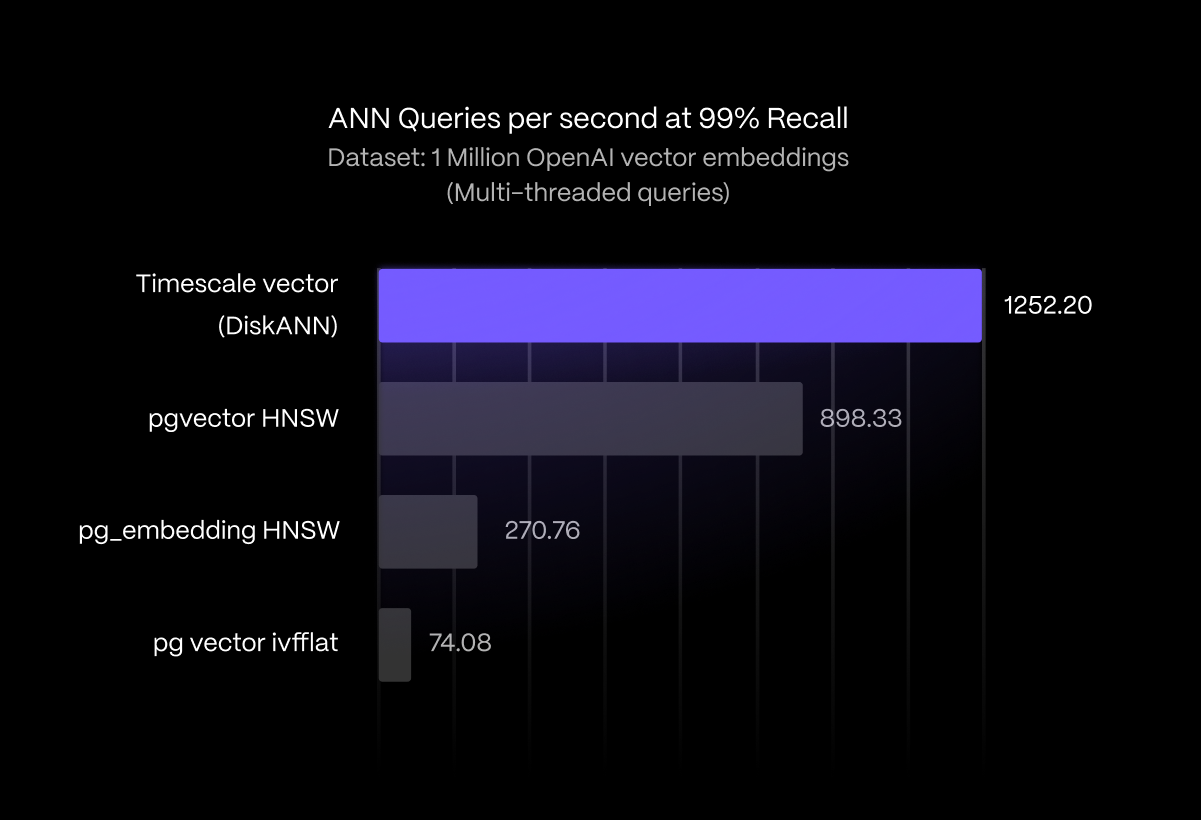
引入新的搜索索引,基于DiskANN算法,Timescale Vector在一百万个OpenAI嵌入数据集上实现了3倍的搜索速度和约99%的召回率。
-
通过自动时间分区和索引,Timescale Vector优化了基于时间的向量搜索查询,支持按时间范围或文档年龄限制向量搜索。
-
将向量嵌入、关系数据和时间序列数据结合在一个PostgreSQL数据库中,简化了AI应用的基础设施。
-
开发者可以利用PostgreSQL的所有数据类型存储和过滤元数据,并将向量搜索结果与关系数据连接,以获得更相关的响应。
-
Timescale Vector提供了灵活的定价、企业级安全性和免费的专家支持,适合生产环境使用。
延伸问答
Timescale Vector如何提升PostgreSQL的向量搜索性能?
Timescale Vector通过引入基于DiskANN算法的新搜索索引,实现了3倍的搜索速度和约99%的召回率,优化了向量搜索性能。
Timescale Vector支持哪些类型的数据?
Timescale Vector支持向量嵌入、关系数据和时间序列数据,允许在一个PostgreSQL数据库中管理这些数据。
如何在Timescale Vector中进行时间范围的向量搜索?
可以通过自动时间分区和索引,利用时间过滤条件来限制向量搜索的时间范围,快速找到相关的嵌入。
Timescale Vector的定价和支持服务如何?
Timescale Vector提供灵活的定价、企业级安全性和免费的专家支持,适合生产环境使用。
开发者如何利用Timescale Vector简化AI应用的基础设施?
开发者可以将向量、关系和时间序列数据结合在一个PostgreSQL数据库中,减少管理多个数据库系统的复杂性。
Timescale Vector如何支持检索增强生成(RAG)应用?
Timescale Vector通过时间上下文检索,优化了基于时间的语义搜索,提升了RAG应用的响应相关性。
