
尼尔森如何在亚马逊EKS上利用无服务器概念进行大数据处理与Spark工作负载
内容提要
尼尔森营销云通过在亚马逊EKS上运行小型本地Spark集群,解决了数据处理中的性能下降和数据倾斜问题,避免了远程数据交换,提升了处理效率,成本降低55%。新架构实现线性扩展,显著提高了每个实例的性能。
关键要点
-
尼尔森营销云每天处理25 TB数据和300亿事件,面临Apache Spark工作负载扩展的挑战。
-
随着集群规模的扩大,实例性能下降,导致每小时工作量减少和处理成本上升。
-
数据倾斜问题导致处理瓶颈,极端情况下可能导致集群失败。
-
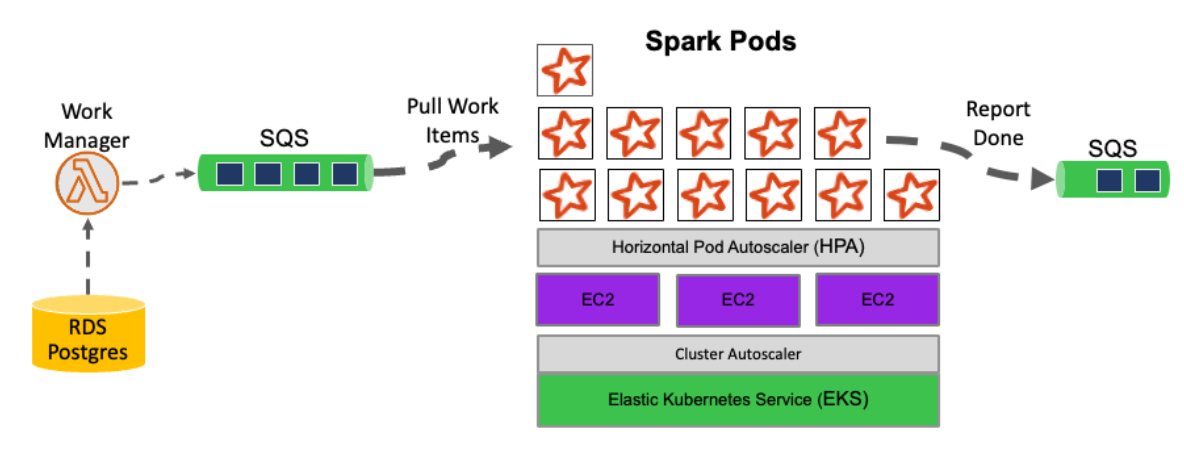
尼尔森决定在亚马逊EKS上运行小型本地Spark集群,避免远程数据交换,提升处理效率。
-
新架构实现线性扩展,处理速度更快,成本降低55%。
-
远程洗牌是数据在Spark实例间交换的过程,速度远低于内存计算,导致处理时间显著增加。
-
通过减少集群规模并增加小型集群,尼尔森消除了每个数据工作项的远程洗牌。
-
新系统设计包括工作项队列、本地模式Spark模块和工作管理器等组件。
-
新系统的性能提升约130%,并保持每GB处理成本接近不变。
-
尼尔森的转型展示了在大数据处理中的重新思考和线性扩展的潜力。
延伸解读
数据倾斜的影响
数据倾斜是大数据处理中的常见问题,导致处理瓶颈和集群效率下降。尼尔森通过减少集群规模和采用小型本地Spark集群,成功消除了远程洗牌,显著提高了处理速度。这一策略为其他面临类似问题的企业提供了借鉴,强调了在设计数据处理架构时考虑数据分布的重要性。
线性扩展的优势
尼尔森的新架构实现了线性扩展,处理效率提高了130%,且成本降低55%。这种设计不仅提升了性能,还使得资源使用更加灵活,能够根据工作量动态调整。这一模式适合需要处理大量数据的企业,尤其是在数据量波动较大的情况下,能够有效应对突发的工作负载。
无服务器架构的应用
尼尔森的转型展示了无服务器架构在大数据处理中的潜力。通过将Spark工作负载转移到亚马逊EKS,尼尔森不仅解决了性能问题,还实现了更高的资源利用率。这一案例为其他企业提供了启示,尤其是在追求成本效益和处理效率的背景下,采用无服务器架构可能是一个有效的解决方案。
延伸问答
尼尔森如何解决数据处理中的性能下降问题?
尼尔森通过在亚马逊EKS上运行小型本地Spark集群,避免了远程数据交换,从而提升了处理效率。
尼尔森在大数据处理上取得了哪些成本节约?
新架构使处理成本降低了55%。
数据倾斜问题对尼尔森的影响是什么?
数据倾斜导致处理瓶颈,降低了集群效率,甚至可能导致集群失败。
尼尔森的新架构是如何实现线性扩展的?
新架构通过使用多个小型本地Spark集群而非单一大型集群,实现了线性扩展。
尼尔森在处理数据时如何避免远程洗牌?
通过减少集群规模并增加小型集群,尼尔森消除了每个数据工作项的远程洗牌。
尼尔森的新系统在性能上有何提升?
新系统的性能提升约130%,并保持每GB处理成本接近不变。
