

为了一个函数名,Go官方吵了两个月:maps.Same提案近日正式通过
Tony Bai
·

函数的位置信息不变性属性与分布属性的比较:在测试中统一但在验证中分离
Apple Machine Learning Research
·
基于学习支持函数的摊销最大内积搜索
Apple Machine Learning Research
·
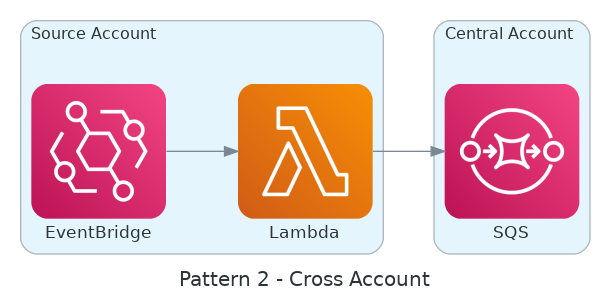
从扩展到一百万个Lambda函数中获得的经验教训
AWS Architecture Blog
·
Stefanie Janine Stölting:pgsql_tweaks 1.0.4版本发布
Planet PostgreSQL
·

记一次hexo-bilibili-bangumi分时函数渲染优化
HCLonely
·
斯特凡妮·雅尼娜·斯特尔廷:pgsql_tweaks 1.0.3版本发布
Planet PostgreSQL
·
再见样板代码!Go 官方新提案:函数一键转接口
Tony Bai
·
