自监督学习使得在无需手动标注数据集的情况下训练神经网络成为可能。通过定义基于数据的预训练任务,自动生成标签并训练编码器以获取表示,这些表示可用于下游任务。常见的预训练任务包括图像补全、旋转预测和对比学习。模型性能评估方法包括线性评估、聚类和可视化。掩码自编码器(MAE)通过掩盖输入的部分补丁进行训练以重建图像,而对比表示学习则通过正负样本的评分函数优化编码器。
本文讨论了在电子商务搜索中微调稀疏嵌入的方法,重点介绍了使用亚马逊ESCI数据集训练SPLADE模型的过程。强调了数据格式化的重要性,以及通过SpladeLoss实现对比学习与稀疏性正则化的平衡。此外,使用Modal的持久存储解决了检查点管理问题,确保了训练过程的稳定性。
嵌入模型通过将输入(如文本或图像)转换为向量,实现相似性检索和个性化推荐,广泛应用于搜索引擎和推荐系统。训练时采用对比学习,使相似输入的嵌入接近,不同输入的嵌入远离。模型评估关注检索效果,常用自动评分模型处理缺乏标准标签的情况。
麻省理工学院等团队提出了AutoSciDACT方法,旨在自动化检测科学数据中的新发现。该方法结合对比学习和统计检验,能够有效识别异常信号,适用于天文学、物理学和生物医学等领域。研究表明,AutoSciDACT在不同数据集上表现优异,推动科学发现向数据驱动转型,提升科研效率。
本文介绍了一种新颖的自监督图表示学习架构,结合了对比学习和生成学习的优点。该框架通过社区感知的节点级和图级对比学习,生成更有效的节点对,并采用多种增强策略,提升了节点分类、聚类和链接预测等任务的性能。评估结果显示,该模型在多个任务上超越了现有最先进的方法。
今天发布了jina-code-embeddings,包含0.5B和1.5B两种参数的代码嵌入模型,支持15种编程语言。0.5B模型在25个代码检索基准中平均表现为78.41%,1.5B为79.04%。这些模型通过对比学习和合成数据训练,展示了在小规模下的优异性能,验证了基础模型的重要性。
MH-Net是一种新型加密流量分类模型,通过构建多视角异构图,挖掘流量字节之间的细粒度关联。该模型结合多任务训练和对比学习,显著提高了流量分类的准确性,尤其在CIC-IoT和ISCX数据集上表现突出,验证了其有效性和先进性。
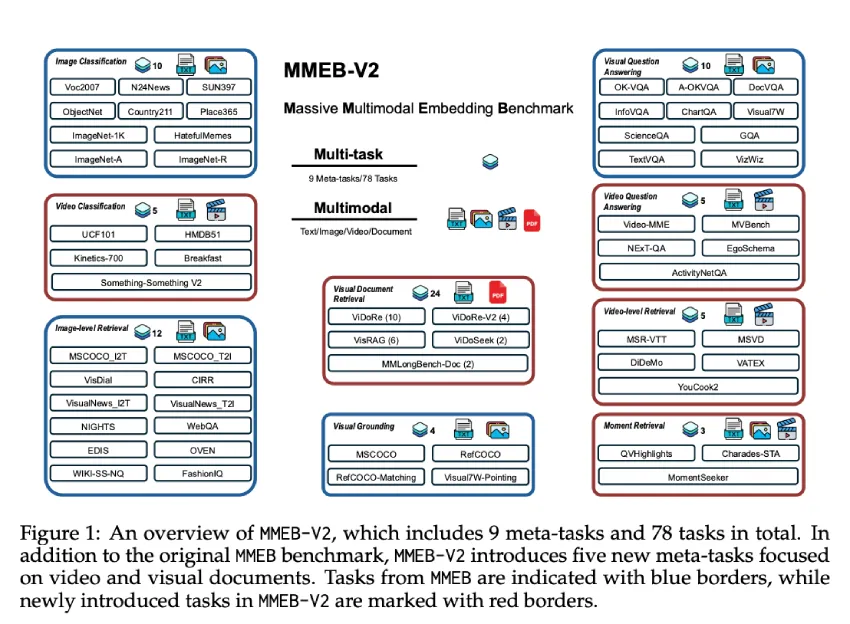
VLM2Vec-V2是一种新型多模态嵌入模型,旨在统一图像、视频和视觉文档检索。基于MMEB-V2基准,支持多种输入模态,采用Qwen2-VL作为骨干,具备动态分辨率和多模态嵌入特性,提升了对比学习的稳定性。实验结果表明,该模型在多模态任务中表现优异。
awesome-mcp-clients 是一个支持多种上下文服务的 Model Context Protocol (MCP) 客户端集合,提升 AI 能力,包含跨平台应用、网页应用和浏览器扩展,提供多语言界面和实时聊天功能。rive-runtime 是 C++ 渲染器,支持艺术板加载和动画查询。smartcomponents 为 .NET 提供 AI 功能,促进开发。contrastors 是 Pytorch 的对比学习工具包,支持多 GPU 训练和 Huggingface 模型。
本研究提出了一种新的任务调制对比学习方法(TMCL),旨在解决机器学习中的灾难性遗忘问题。该方法通过自上而下的调制,即使在仅有1%标签的情况下,也能显著提升分类增量和迁移学习效果,表明其在稳定性与可塑性之间的平衡中至关重要。
本研究提出了一种音频视觉联合学习方法(MACB-DF),旨在解决多模态检测中的学习不平衡问题。该方法通过对比学习促进模态融合,实验结果表明在多个深度伪造数据集上达到了95.5%的准确率,并提升了跨数据集的泛化能力。
本研究探讨了语音对话中声音反馈(如“嗯”、“是的”、“好吧”)的感知韵律相似性。结果表明,光谱和自监督语音表征在编码韵律方面优于音高特征,尤其在同一说话者的反馈中,通过对比学习可进一步优化这些表征。
本研究提出了一种原型增强框架,旨在解决联邦学习中因领域异质性导致的全局模型收敛问题。通过引入联邦增强原型对比学习(FedAPC),显著提升了模型的泛化能力和稳健性,实验结果表明其性能优于现有技术。
本研究提出了一种名为WiMAE的无线掩蔽自编码器基础模型,专注于多天线无线信道数据集的自监督学习。通过结合对比学习与重构任务,开发的ContraWiMAE显著提升了模型的表示能力和数据效率,为无线信道表示学习奠定了基础。
Tangu Mod是Voyage AI的联合创始人,他在WE8播客中分享了企业AI和检索增强生成(RAG)的见解。他强调了在金融和法律等领域开发特定嵌入模型的重要性,并讨论了对比学习和数据增强在文本与图像嵌入中的应用。他指出,尽管合成数据生成成本高,真实数据的多样性更具优势,并提到AI的模块化发展使得使用AI变得更加简单。
本研究提出了一种新的洛伦兹知识聚合机制及三种模型增强技术,解决了对比学习在用户-物品二部图和知识图中捕捉层次结构的不足,推荐效果提升达11.03%。
本研究提出DFA-CON对比学习框架,旨在有效检测生成式AI工具对视觉艺术创作的版权侵犯与伪造问题。DFA-CON通过建立原创艺术作品与伪造作品之间的亲和力,展现出强大的检测性能,超越了现有预训练模型。
本研究提出CSE-SFP方法,旨在提高无监督句子表示学习的效率。该方法通过一次前向传播实现有效的对比学习,显著提升嵌入质量,降低训练时间和内存消耗,对文本表示领域具有重要影响。
本研究提出了OmicsCL模块化对比学习框架,旨在解决多组学数据中无监督学习疾病亚型的难题,挖掘与患者生存相关的临床集群,为个性化医疗提供新思路。
本研究提出了SacFL框架,旨在解决终端设备在持续学习中面临的存储资源有限和任务转移检测能力不足的问题。通过编码器-解码器结构和对比学习机制,显著降低了存储需求,并实现了自主的数据转移检测。实验结果验证了该框架在资源受限设备上的有效性。
完成下面两步后,将自动完成登录并继续当前操作。