


苹果隐私保护机器学习与人工智能研讨会 2026
Apple Machine Learning Research
·

在日常设备上实现隐私保护的人工智能训练
MIT News - Artificial intelligence
·

现已上线:全球最强大的药物发现与开发AI工厂
NVIDIA Blog
·
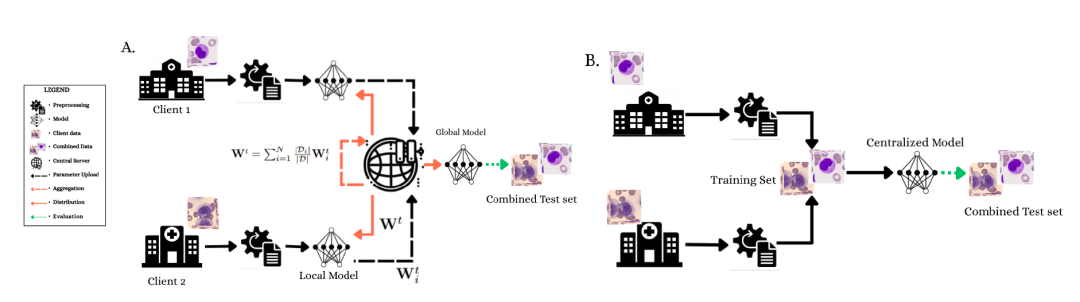
不共享数据,也能联合训练!UCL团队用联邦学习重塑血液形态学检查
HyperAI超神经
·

为语音识别启用差分隐私的联邦学习:基准测试、自适应优化器与梯度裁剪
Apple Machine Learning Research
·

可扩展且安全的边缘 AI 联邦学习架构
实时互动网
·
