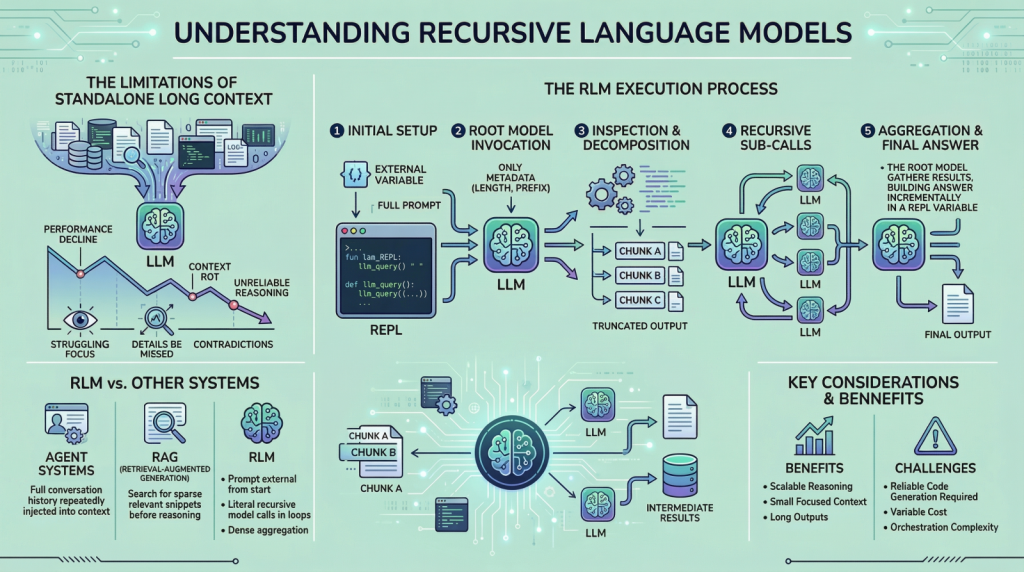
递归语言模型(RLM)旨在解决长输入推理中的上下文衰退问题。与传统模型不同,RLM通过外部运行时和递归子调用处理信息,保持内部上下文小而专注,从而提高处理效率,尤其在信息密集的复杂任务中表现出明显优势。
上下文衰退影响企业AI和大型语言模型(LLM)的表现。旧数据未被清除,导致信息混乱和推理能力下降。企业需监控关键数据指标,清除过时数据,以提升AI的准确性和效率。
大型语言模型(LLM)在处理长上下文时会出现准确性下降的问题,称为“上下文衰退”。斯坦福研究表明,信息位置影响准确性,位置越靠中间,准确率越低。上下文衰退导致响应质量下降、计算成本增加和架构复杂性提升。解决方案包括外部记忆架构和语义缓存,以保持固定上下文窗口并动态检索相关信息。
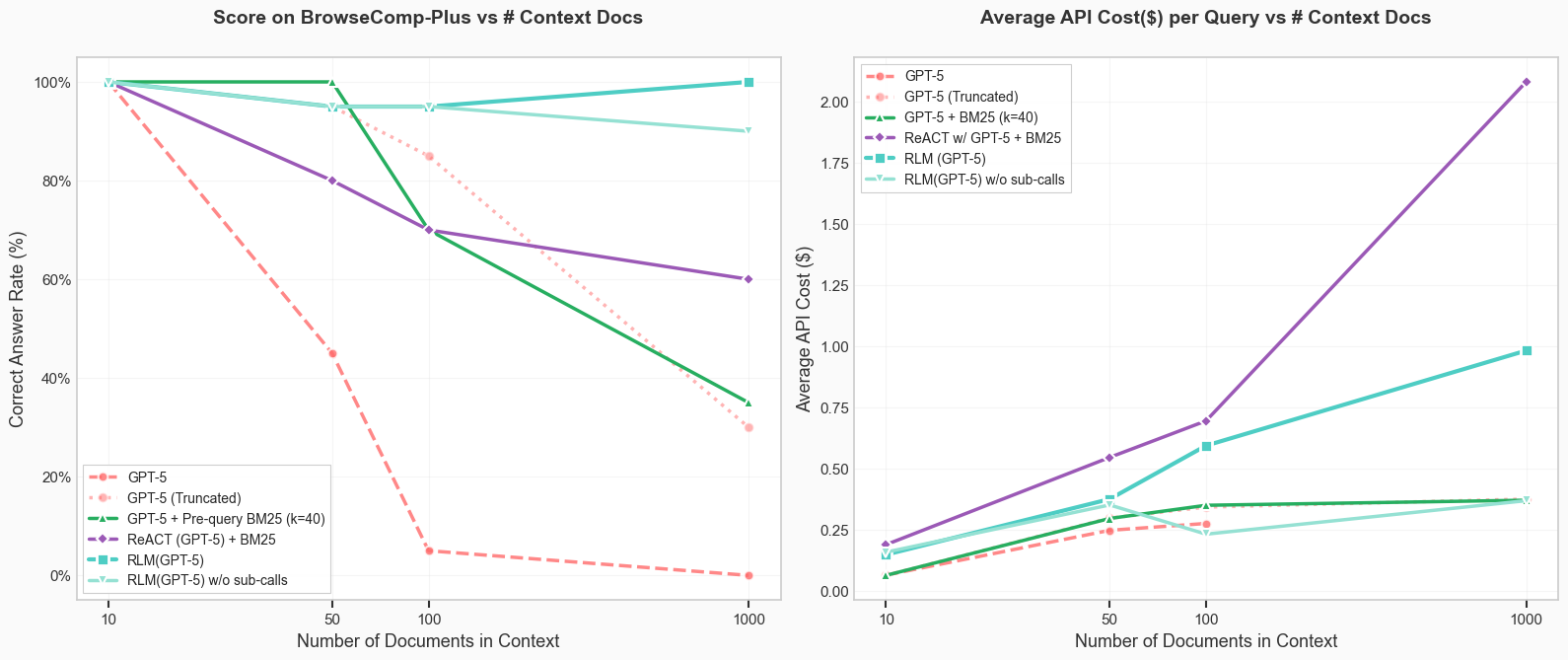
递归语言模型(RLM)是一种推理策略,允许语言模型在REPL环境中递归处理无限长度的输入上下文。研究表明,使用RLM的GPT-5-mini在长上下文基准测试中表现优于GPT-5,且查询成本更低。RLM通过将上下文视为变量,有效应对“上下文衰退”现象,提升了模型处理大规模文本的能力。
完成下面两步后,将自动完成登录并继续当前操作。