
关于递归语言模型的所有知识
内容提要
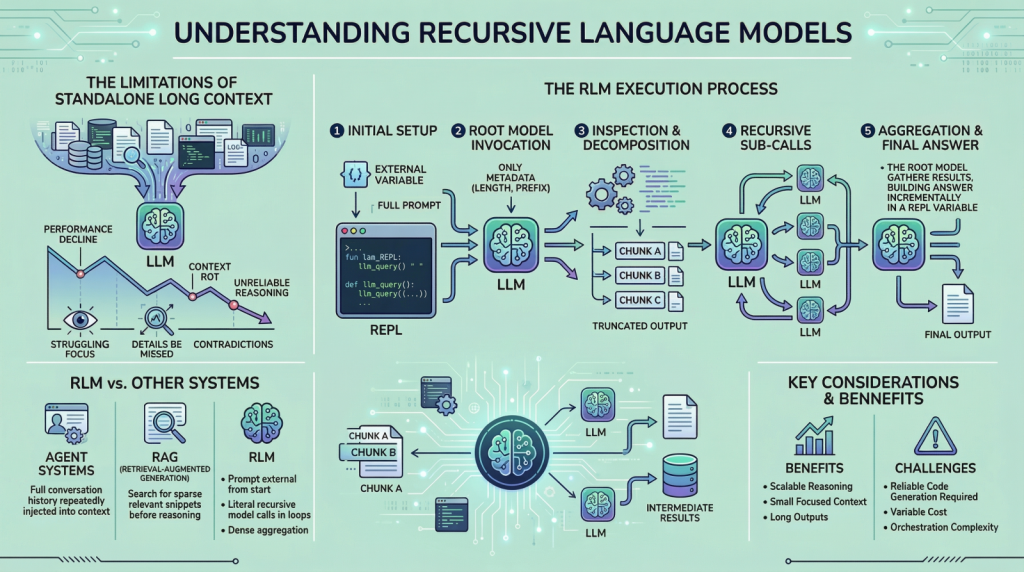
递归语言模型(RLM)旨在解决长输入推理中的上下文衰退问题。与传统模型不同,RLM通过外部运行时和递归子调用处理信息,保持内部上下文小而专注,从而提高处理效率,尤其在信息密集的复杂任务中表现出明显优势。
关键要点
-
递归语言模型(RLM)旨在解决长输入推理中的上下文衰退问题。
-
传统模型在处理长输入时,往往会出现信息丢失和推理不准确的问题。
-
RLM通过外部运行时和递归子调用来处理信息,保持内部上下文小而专注。
-
RLM允许模型主动探索和处理输入,而不是被动吸收整个提示。
-
RLM的工作流程包括初始化持久环境、调用根模型、检查和分解提示、发出递归子调用以及组装最终答案。
-
RLM与代理系统和检索系统不同,RLM保持提示在外部并通过递归调用来处理信息。
-
RLM的缺点包括计算成本的转移和对模型编写可靠代码的要求。
延伸解读
递归语言模型的优势
递归语言模型(RLM)通过将输入信息外部化,避免了传统模型在处理长输入时的上下文衰退问题。这种方法使得模型能够在信息密集的任务中更有效地聚焦于关键内容,从而提高推理的准确性和效率。
RLM的局限性
尽管RLM在处理长输入方面表现出色,但其计算成本并未减少,反而可能因多次调用而增加。此外,模型需要具备编写可靠代码的能力,若代码质量不高,可能导致过多的子调用或无法正确终止,增加了工程上的挑战。
与传统模型的比较
与传统的长上下文模型不同,RLM不依赖于一次性吸收整个输入,而是通过递归调用逐步处理信息。这种方法特别适合需要在大量信息中进行聚合和推理的复杂任务,能够有效避免信息丢失和推理不准确的问题。
延伸问答
递归语言模型(RLM)解决了什么问题?
RLM旨在解决长输入推理中的上下文衰退问题,避免信息丢失和推理不准确。
递归语言模型与传统模型有什么不同?
RLM通过外部运行时和递归子调用处理信息,而传统模型则是被动吸收整个提示。
RLM的工作流程是怎样的?
RLM的工作流程包括初始化持久环境、调用根模型、检查和分解提示、发出递归子调用以及组装最终答案。
使用递归语言模型的优缺点是什么?
优点是能有效处理长输入,缺点包括计算成本的转移和对模型编写可靠代码的要求。
RLM适合哪些类型的任务?
RLM适合处理长输入且任务复杂的情况,特别是当总结或检索会丢失重要信息时。
RLM如何保持内部上下文小而专注?
RLM通过将输入视为外部环境,仅提供元数据和访问指令,避免直接读取完整输入。
