RLM(递归语言模型)通过在代码沙箱中执行推理,克服了传统AI在处理长上下文时的局限性。它能够直接编写程序,解决记忆不足的问题,提升复杂任务的处理能力。RLM将大问题拆解为小问题,缓存中间结果,提高效率和稳定性。该技术在合同解析、发票处理和知识库检索等领域表现优异,标志着AI工程的重大变革。
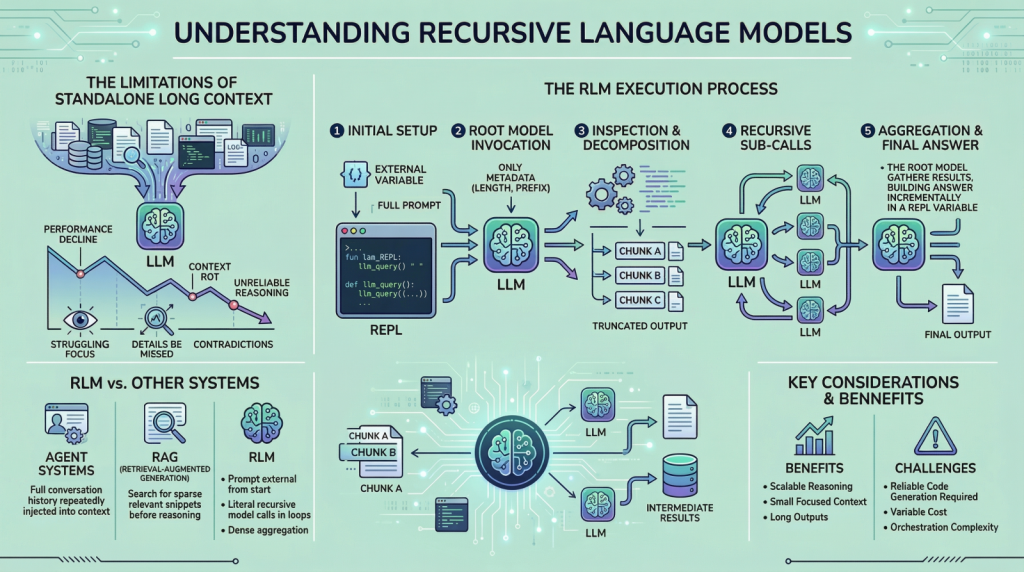
递归语言模型(RLM)旨在解决长输入推理中的上下文衰退问题。与传统模型不同,RLM通过外部运行时和递归子调用处理信息,保持内部上下文小而专注,从而提高处理效率,尤其在信息密集的复杂任务中表现出明显优势。
文章讨论了语言模型的未来发展,认为现有的神经语言模型被低估,具有更大潜力。随着技术进步,语言模型与支架的界限逐渐模糊,创新想法有望推动领域发展。作者对递归语言模型(RLMs)寄予厚望,期待其实现更强的推理能力,并期待其他新思路的出现。
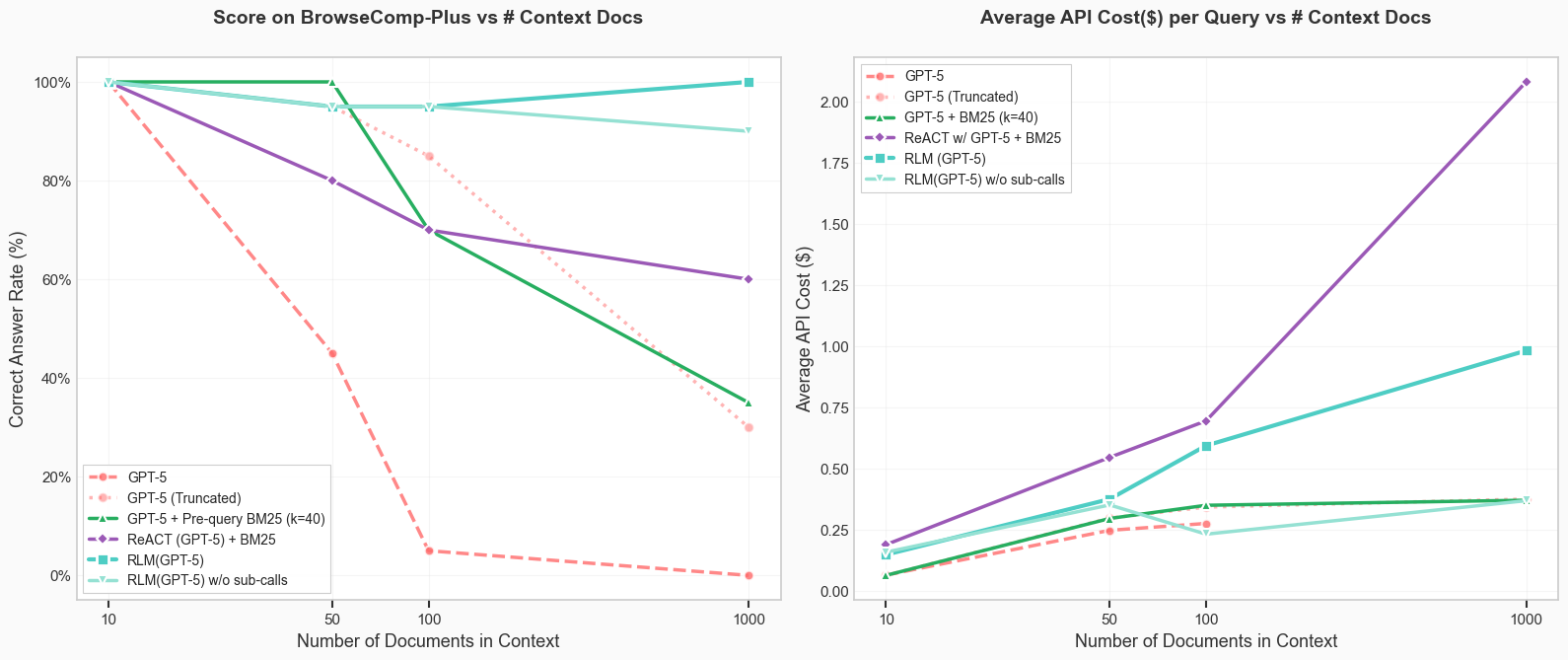
麻省理工学院的研究人员提出了一种递归语言模型(RLM),旨在提升大语言模型(LLM)在长上下文任务中的表现。RLM通过编程环境递归处理输入,能够处理比基础LLM长100倍的提示。其核心在于利用编程语言(如Python)生成代码,以分块或搜索正则表达式等方式预处理提示。研究表明,RLM在长上下文基准测试中优于其他策略,有效解决了上下文窗口限制的问题。
MIT研究团队提出递归语言模型RLM,解决大模型在处理超长文本时的上下文腐烂问题。RLM通过交互式Python环境动态拆解任务,实现千万级token处理能力,显著提升推理性能,无需修改模型架构。
递归语言模型(RLM)是一种推理策略,允许语言模型在REPL环境中递归处理无限长度的输入上下文。研究表明,使用RLM的GPT-5-mini在长上下文基准测试中表现优于GPT-5,且查询成本更低。RLM通过将上下文视为变量,有效应对“上下文衰退”现象,提升了模型处理大规模文本的能力。
完成下面两步后,将自动完成登录并继续当前操作。