
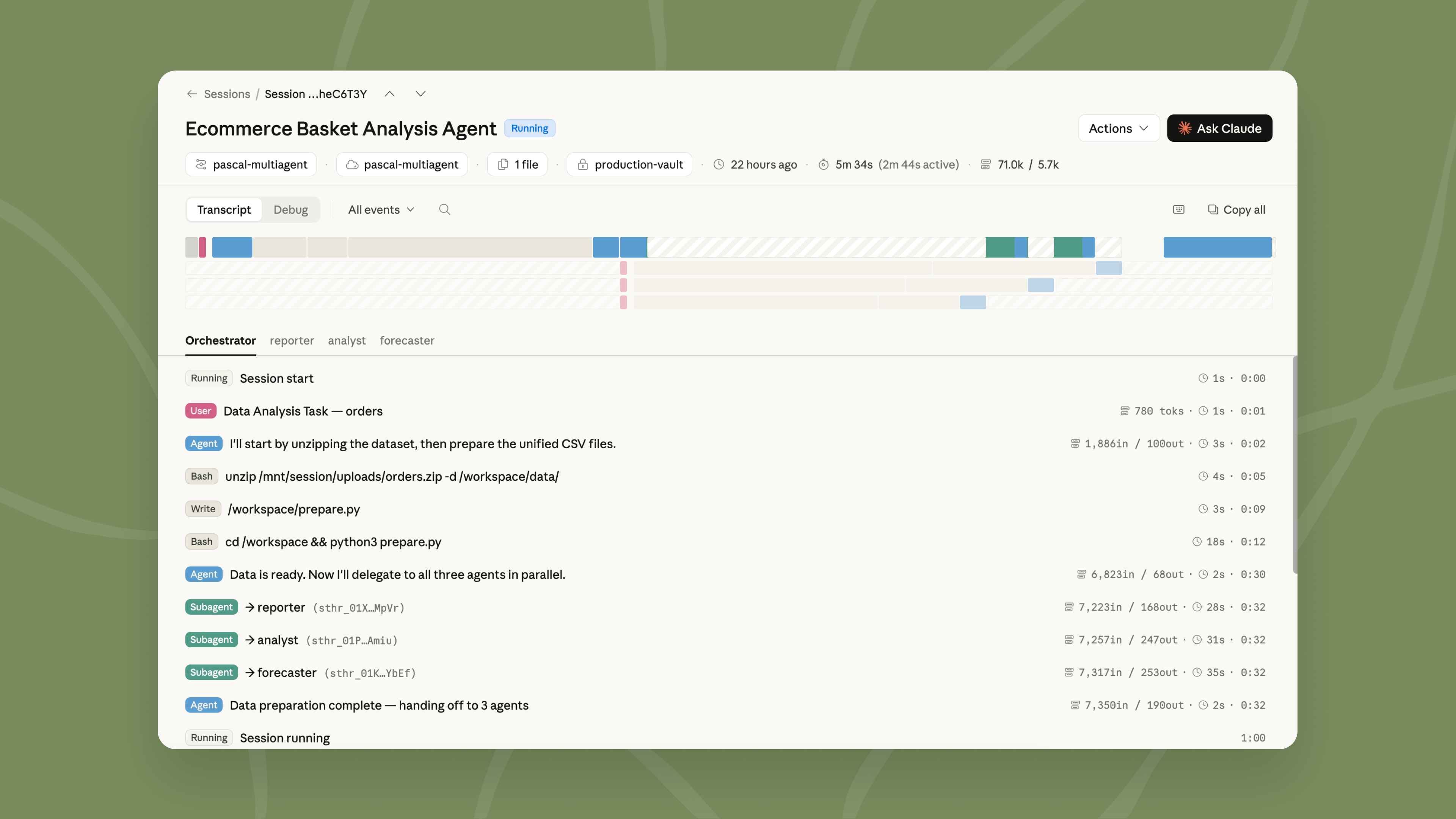
Claude管理代理的新功能:梦境、结果和多代理编排
Claude
·
.jpg)
IT领导者如何衡量代理AI项目的投资回报率
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
/filters:no_upscale()/articles/evaluating-ai-agents-lessons-learned/en/resources/189figure-1-1773307287862.jpg)
实践中评估AI代理:基准、框架与经验教训
InfoQ
·

新研究重新评估 AGENTS.md 文件对 AI 编码的价值
InfoQ
·

Agentic AI基础设施实践经验系列(六):Agent质量评估
亚马逊AWS官方博客
·

真正重要的用户体验指标
DEV Community
·
通过分解缩放曲线指导数据收集
BriefGPT - AI 论文速递
·
