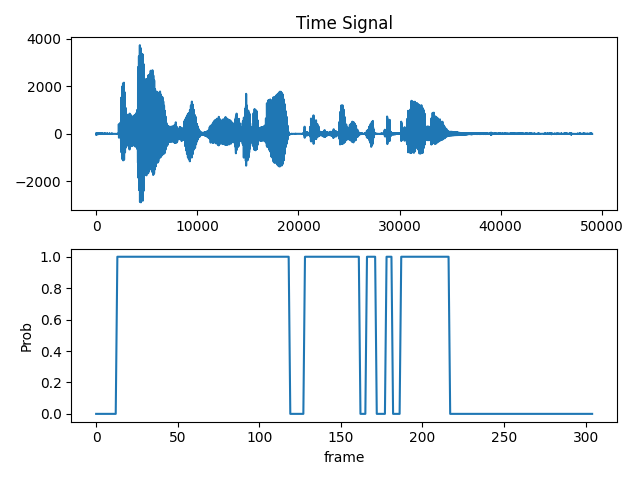
语音活动检测(VAD)用于识别语音的起止点,以节省带宽并提高语音识别精度。本文介绍了一种适用于计算受限设备的实时统计模型VAD,结合噪声估计,能够在低信噪比下有效区分语音与非语音区域。
本研究提出了一种基于LLaVA的高效语义通信框架,通过优化图像切片和用户注意力,显著提高了低信噪比环境下用户与云服务器的交互效率、准确性和资源利用率。
本文介绍了一种新方法DART,通过结合静态和动态脑网络进行脑功能分析,提高性能和可解释性,解决低信噪比问题,为预测提供洞察。DRAT在神经影像研究中展示出有希望的方向,有助于理解脑机构和神经回路的作用。
本文介绍了一种名为ACE-HetEM的无监督深度学习架构,可在低信噪比和未知姿态条件下从2D图像中重建三维结构,并实现构象分类和姿态估计的解耦。模拟实验结果显示,ACE-HetEM在姿态估计方面准确性可比,重建分辨率高于非摊销方法,适用于真实实验数据集。
完成下面两步后,将自动完成登录并继续当前操作。